Тема 4
Data Engineering, Big Data та Machine Learning на базі Google Cloud Platform
(GCP)
Питання, що розглядаються: хмарна інфраструктура Google .
Хмарна інфраструктура Google (рис.2) розташована в п’яти основних
географічних точках, Північна Америка, Південна Америка, Європа, Азія та
Австралія [3-8, 16-17].

Рисунок 2
Наявність кількох місць обслуговування є важливим, оскільки вибір
місця розташування застосування впливає на такі якості, як доступність,
довговічність. І затримка, яка вимірює час, потрібна для переміщення пакета
інформації від джерела до місця призначення. Кожне з цих місць поділено на
кілька різних регіонів і зон. Регіони являють собою самостійні географічні
області і складаються із зон. Наприклад, Лондон або Західна Європа 2 – це
регіон, який наразі містить три різні зони. Зона – це область, де розгортаються
ресурси Google Cloud. Наприклад, скажімо, ви запускаєте віртуальну машину за
допомогою обчислювальної системи (рис.3).
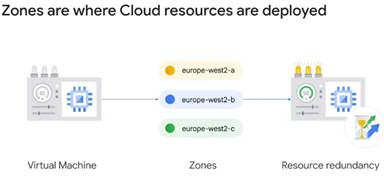
Рисунок 3 – Зона, де розгортаються
ресурси Google Cloud
Трохи більше про обчислювальний механізм, він працюватиме в зоні,
яку ви вкажете, щоб забезпечити резервування ресурсів. Зональні ресурси діють в
межах однієї зони, що означає, що якщо зона стає недоступним, ресурси також не
будуть доступні. Google Cloud дозволяє користувачам вказувати географічні
розташування для запуску служб і ресурси.
У багатьох випадках можна навіть вказати розташування на зоні,
регіональний чи міжрегіональний рівень. Це корисно для наближення програм до
користувачів у всьому світі та також для захисту, якщо є проблеми з цілим
регіоном, скажімо, внаслідок стихійного лиха (рис.4).
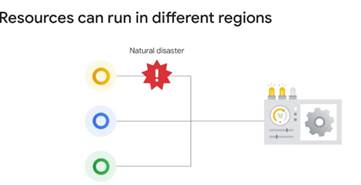
Рисунок 4 – Проблеми з цілим
регіоном
Деякі служби Google Cloud підтримують розміщення ресурсів у тому,
що ми називаємо мультирегіоном (рис.5).
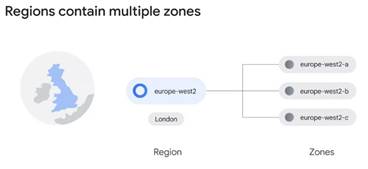
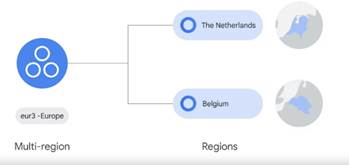
Рисунок 5 – Google Cloud
підтримують розміщення ресурсів у мультирегіонах
Наприклад, багаторегіональні конфігурації хмарного гайкового ключа
дозволяють тиражувати дані бази даних не лише в кількох зонах. Але в кількох
зонах у кількох регіонах, як визначено конфігурацією примірника. Ці додаткові
репліки дозволяють читати дані з низькою затримкою кілька місць поблизу або в
межах регіонів у конфігурації.
Подібно до Нідерландів і Бельгії, Google Cloud наразі підтримує
103 зони в 34 регіонах, хоча це весь час збільшується. Найновішу інформацію
можна знайти на cloud.google.com/about locations.
Звернемо увагу на середній шар інфраструктура Google Cloud,
обчислення та сховище. Ми почнемо з обчислень. Організації зі зростаючими
потребами в даних часто потрібна значна обчислювальна потужність для виконання
завдань із великим обсягом даних. І оскільки організації планують майбутнє,
потреба в обчислювальній потужності тільки зростає.
Google пропонує низку комп’ютерних послуг. Перший — Compute Engine
(рис.6). Compute Engine — це пропозиція IaaS або інфраструктура як послуга, яка
забезпечує обчислення, зберігання та мережа практично схожі на фізичні центри
обробки даних.
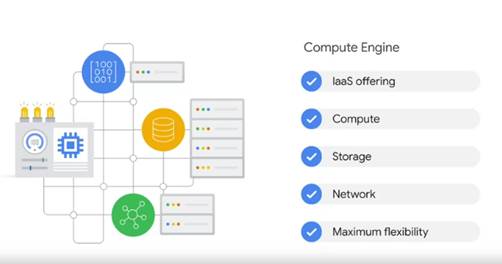
Рисунок 6 – Compute Engine
Ви використовуєте віртуальний комп’ютер і сховище ресурси так
само, як ви керуєте ними локально. Compute Engine забезпечує для них
максимальну гнучкість, які вважають за краще самостійно керувати примірниками
сервера (рис.7).

Рисунок 7 – Compute Engine
Другий — Google Kubernetes Engine або GKE. GKE запускає
контейнерні програми хмарне середовище на відміну від on окрема віртуальна
машина, наприклад Compute Engine. Контейнер представляє код зі усіма залежностями.
Третій обчислювальний сервіс Google пропонує App Engine, повністю
керована пропозиція PaaS або платформа як послуга (рис.8).

Рисунок 8 – App Engine
Пропозиції PaaS прив’язують код до бібліотек, які надають доступ
до потреб додатків інфраструктури. Це дозволяє отримати більше ресурсів,
зосереджено на логіці програми.
Крім того, є хмарні функції, які виконують код реагування на
події, як коли новий файл завантажується в Cloud Storage. Це повністю
безсерверне середовище виконання, це означає, що вам не потрібно встановлювати
будь-яке локальне програмне забезпечення для запуску коду, і ви вільні від
надання та керування серверами.
Часто згадується «Хмарні функції». функціонує як послуга (рис.9).
Рисунок 9 – Хмарні функції
Нарешті, є Cloud Run, повністю кероване обчислення платформа, яка
дозволяє виконувати запити або робочі навантаження без стану, керовані подіями
не турбуючись про сервери (рис.10).

Рисунок 10 – Cloud Run
Це абстрагує все управління інфраструктурою, щоб ви могли
зосередитися на написанні коду.
Він автоматично змінює масштаб від нуля, вам ніколи не доведеться
турбуватися про налаштування масштабу. Cloud Run стягує плату лише за ресурси,
які ви використовуєте, тому ви ніколи не платите за надлишок ресурсів.
Давайте розберемося, як Google Photos залежить від обчислювальних
можливостей надано Google Cloud для запровадити стабілізацію відео. Google
Photos пропонує функцію називається автоматичною стабілізацією відео.
Це займає нестабільне відео, як той, хто був захоплений під час
верхової їзди на задній частині мотоцикла, і стабілізує його, щоб мінімізувати
рух. Давайте розглянемо приклад технологія, яка потребує великої обчислювальної
потужності. Почати відтворення відео о 2:47 і дотримуватися тексту 2:47. Щоб
стабільність відео працювала належним чином, вам потрібні належні дані. Це
включає саме відео, це справді велика колекція окремих зображень, разом із
даними часового ряду про положення камери, і орієнтування від бортового
гіроскопа, і рух від об’єктива камери. Для короткого відео може знадобитися
понад мільярд точок даних, щоб підживити модель ML для створення стабілізованої
версії. Станом на 2020 рік приблизно 28 мільярдів фотографій і відео
завантажувалися в Google Photos щотижня, з більш ніж чотирма трильонами фотографій всього зберігається в сервісі.
Щоб переконатися, що ця функція працює як призначено і точно,
команда Google Photos потребувала розробки, навчання, і обслуговувати
високоефективну модель машинного навчання на мільйони відео. Це великий набір
навчальних даних. Так само, як обладнання на стандартний персональний комп'ютер
може не бути достатньо потужний для обробки робота з великими даними для
організації, апаратна частина смартфона не є потужною достатньо для навчання
складних моделей ML.
Ось чому Google тренує виробничі моделі машинного навчання в
велика мережа центрів обробки даних, лише для того, щоб потім розгорнути менші
навчені версії моделі смартфона в апаратному забезпеченні персонального
комп’ютера.
Але звідки береться вся обчислювальна потужність? Згідно зі звітом
Стенфордського університету про індекс ШІ за 2019 рік, до 2012 року, отримані
результати штучного інтелекту тісно з законом Мура, з необхідною обчислювальною
потужністю, яка використовується в найбільше навчання ШІ подвоюється кожні два
роки. У звіті йдеться, що з 2012 р. необхідна обчислювальна потужність була
подвоюється приблизно кожні три з половиною місяці. Це означає, що виробники
обладнання мають зіткнутися з обмеженнями та процесорами, які є центральними
процесорами, і графічні процесори, які є графічними процесорами, більше не може
адекватно масштабуватися задовольнити швидкий попит на машинне навчання. Щоб
допомогти подолати цю проблему, у 2016 році Google представив блок обробки тензорів,
або TPU. TPU розроблено Google на замовлення спеціальні інтегральні схеми
використовується для прискорення навантажень машинного навчання.
TPU діють як доменне апаратне забезпечення на відміну від
апаратного забезпечення загального призначення з процесорами та графічними
процесорами. Це дозволяє підвищити ефективність адаптуючи архітектуру до потреб
потреби в обчисленнях у такому домені як множення матриці в машинному навчанні.
TPU, як правило, швидше, ніж поточні GPU ЦП для додатків ШІ та машинного
навчання. Вони також значно енергоефективніші. Хмарні TPU інтегровані в
продукти Google, створення найсучаснішого обладнання та доступні суперобчислювальні
технології клієнтам Google Cloud.
Зберігання (Storage)
Тепер, коли ми дослідили обчислення та навіщо вони потрібні для
великих даних і завдань ML, тепер розглянемо сховище. Для належних можливостей
масштабування обчислення та сховище відокремлені. Це одна з головних
відмінностей між хмарними та настільними обчисленнями. У хмарних обчисленнях
обмеження обробки не пов’язані з дисками зберігання.
Для більшості програм потрібна база даних і якесь рішення для
зберігання даних. З Compute Engine можна встановити і запустити базу даних на
віртуальній машині так само, як це зробили б в центрі обробки даних. Крім того,
Google Cloud пропонує повністю керовані бази даних і служби зберігання.
До них належать: Хмарне сховище Cloud Bigtable, Cloud SQL, Cloud
Spanner, Firestore (рис.11), BigQuery. Мета цих продуктів — зменшити час і
зусилля, необхідні для зберігання даних.

Рисунок 11 – Firestore
Це означає створення еластичного відра для зберігання
безпосередньо у веб-інтерфейсі або через командний рядок, наприклад, у Cloud
Storage.
Google Cloud пропонує реляційні та нереляційні бази даних і
всесвітнє зберігання об’єктів (рис.12). Незабаром ми розглянемо ці варіанти
більш детально. Вибір правильного варіанту для частого зберігання та обробки
даних залежить від типу даних, які необхідно зберегти і потреби бізнесу.

Рисунок 12 – Реляційні та
нереляційні бази даних
Почнемо з неструктурованих та структурованих даних.
Неструктуровані дані — це інформація, що зберігається в не табличній формі,
наприклад як документи, зображення та аудіофайли. Неструктуровані дані зазвичай
підходять для хмарного сховища, але BigQuery тепер пропонує можливість також
зберігати неструктуровані дані.
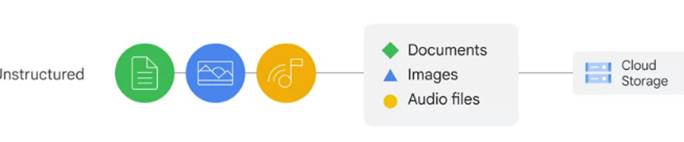
Рисунок 13 – Неструктуровані дані
Хмарне сховище – це керований сервіс для зберігання
неструктурованих даних. Хмарне сховище – це служба для зберігання ваших
об’єктів у Google Cloud. Об'єкт - це незмінна частина даних, що складається з
файлу будь-якого формату. Ви зберігаєте об’єкти в контейнерах, які називаються
відрами. Усі сегменти пов’язані з проектом, і ви можете згрупувати свої проекти
за організацією. Кожен проект, сегмент і об’єкт у Google Cloud є ресурсом у
Google Cloud такі речі, як екземпляри Compute Engine.
Після створення проекту ви можете створювати сегменти Cloud
Storage, завантажувати об’єкти у свій відра та завантажувати об’єкти з ваших
відер. Кілька прикладів включають обслуговування вмісту веб-сайту, зберігання
даних для архівування та аварійного відновлення, і розповсюдження великих
об’єктів даних кінцевим користувачам через пряме завантаження.
Cloud Storage має чотири основні класи зберігання.
Перший — стандартне сховище. Стандартне сховище вважається
найкращим для часто використовуваних або «гарячих» даних. Це також чудово
підходить для даних, які зберігаються лише протягом короткого періоду часу.
Другий клас зберігання — Nearline Storage. Це найкраще для
зберігання даних, до яких звертаються рідко, як-от одноразове читання або зміна
даних в середньому на місяць або менше. Приклади включають резервне копіювання
даних, довгостроковий мультимедійний вміст або архівування даних.
Третій клас зберігання — Coldline Storage. Це також недорогий
варіант для зберігання даних, до яких часто звертаються. Однак, порівняно з
Nearline Storage, Coldline Storage призначений для читання або модифікації
дані, щонайбільше, один раз на 90 днів.
Четвертий клас зберігання — архівне зберігання. Це найдешевший
варіант, який ідеально використовується для архівування даних,
онлайн-резервного копіювання та катастроф відновлення. Це найкращий вибір для
даних, до яких планується мати доступ рідше одного разу на рік, тому що це має
вищі витрати на доступ до даних і операції та мінімальний термін зберігання 365
днів (рис.14).

Рисунок 14 – Основні класи
зберігання
Крім того, є структуровані дані, які представляють інформацію, що
зберігається в таблиці, рядки, і стовпці. Структуровані дані бувають двох
типів: транзакційні навантаження та аналітичні навантаження (рис.15).
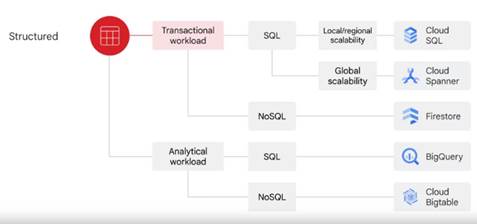
Рисунок 15 – Типи структурованих
даних
Робочі навантаження на транзакції походять від систем
онлайн-обробки транзакцій, які використовуються, коли вони швидкі для створення
записів на основі рядків, потрібні вставки та оновлення даних. Зазвичай це
потрібно для збереження знімка системи. Вони вимагають відносно
стандартизованих запитів, які впливають лише на кілька записів.
Крім того, існують аналітичні робочі навантаження, які випливають
із систем онлайнової аналітичної обробки, які використовуються, коли потрібно
прочитати цілі набори даних. Вони часто вимагають складних запитів, наприклад,
агрегування. Коли ви визначите, чи є навантаження транзакційними чи
аналітичними, необхідно визначити, чи буде доступ до даних за допомогою SQL чи
ні. Отже, якщо ваші дані є транзакційними і вам потрібно отримати до них доступ
за допомогою SQL, тоді Cloud SQL і Cloud Spanner – два варіанти.
Cloud SQL найкраще працює для локального та регіонального
масштабування, а Cloud Spanner – найкраще для глобального масштабування бази
даних. Якщо доступ до транзакційних даних здійснюватиметься без SQL, Firestore
може бути найкращим варіантом.
Firestore — це транзакційна NoSQL документоорієнтована база даних.
Якщо у вас є аналітичні робочі навантаження, які потребують команд SQL,
BigQuery, ймовірно, найкращий варіант. BigQuery, рішення для сховища даних від
Google, дозволяє аналізувати набори даних у петабайтному масштабі. Крім того,
Cloud Bigtable надає масштабоване рішення NoSQL для аналітичних робочих
навантажень. Це найкраще для високопродуктивних програм у режимі реального
часу, які потребують лише мілісекунди затримка.
Історія великих даних і продуктів ML (рис.16).
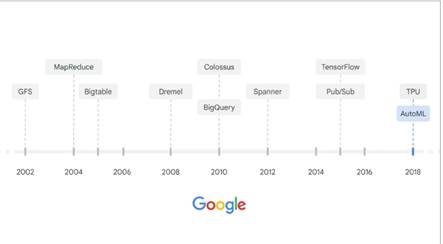
Рисунок 16 – Історія великих даних
Останній рівень інфраструктури Google Cloud, який ще потрібно
вивчити це великі дані та продукти машинного навчання. Розглядається еволюція
фреймворків обробки даних.
Великі дані та категорії продуктів ML
Google пропонує ряд продуктів для великих даних і машинного
навчання. Отже, як ви знаєте, що найкраще підходить для потреб вашого бізнесу?
Розглянемо ближче список продуктів, які можна розділити на чотири загальні
категорії разом робочий процес перетворення даних на ШІ: прийом і процес,
зберігання, аналітика, і машинне навчання. Розуміння цих категорій продуктів
може допомогти звузити вибір.
Перша категорія — прийом і процес (рис.17), які включають
продукти, які використовуються для аналізу як даних у реальному часі, так і
пакетних даних. Список включає:
· Pub/Sub,
· Потік даних,
· Dataproc,
−
Cloud Data Fusion.
Dataflow і Pub/Sub можуть отримувати потокові дані.
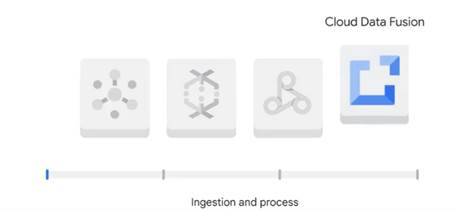
Рисунок 17 – Прийом і процес
Друга категорія продуктів – це зберігання даних (рис.18), є п'ять
продуктів зберігання:
· Хмарне сховище
· Хмарний SQL
· Cloud Spanner
· Cloud Bigtable і
· Firestore
Cloud SQL і Cloud Spanner є реляційними базами даних Bigtable і
Firestore є базами даних NoSQL.
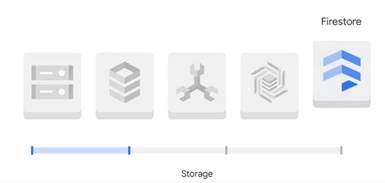
Рисунок 18 – Зберігання даних
Третя категорія продуктів – аналітика.
Основним інструментом аналітики є BigQuery.
BigQuery ̶ це повністю
кероване сховище даних, яке можна використовувати для аналізу даних за
допомогою SQL команди. Окрім BigQuery, можна аналізувати дані та візуалізувати
результати за допомогою: Looker, Looker Studio.
І останньою категорією продуктів є машинне навчання, або ML.
Продукти ML включають як платформу розробки ML, так і рішення AI: Основним
продуктом платформи розробки ML є Vertex AI, що включає продукти та технології:
· AutoML.
· Vertex AI Workbench.
· TensorFlow.
Рішення штучного інтелекту побудовані на платформі розробки ML і
містять найсучасніші продукти для задоволення як горизонтальних, так і
вертикальних потреб ринку. До них належать:
· Document AI
· Contact Center AI
· Retail Product Discovery
· Healthcare Data Engine
Ці продукти відкривають статистичні дані, які можуть надати лише
великі обсяги даних. Ми досліджуватимемо варіанти машинного навчання та робочий
процес разом із цими продуктами більш детально пізніше (рис.19).


