Тема 5
Основні моделі представлення знань. Онтологія
Питання, що розглядаються: онтологія.
Обсяги інформації з кожним роком стрімко збільшуються,
відбувається перевантаження інформацією. Потік інформації надходить з науки,
бізнесу, Інтернету та інших джерел. Але знання є не лише у людини, вони
містяться також у накопичених даних, які необхідно аналізувати. Такі знання
часто називають «прихованими» [14, 16].
Очевидно, що для виявлення «прихованих» знань потрібно
застосовувати спеціальні методи автоматичного аналізу даних, за допомогою яких
доводиться «добувати» знання із величезного об'єму інформації.
Електронні освітні ресурси (ЕОР) активно розробляються та
впроваджуються в навчальний процес . Сучасні програмні засоби (ПЗ), в тому
числі і системи дистанційного навчання (СДН), успішно вирішують завдання
створення, зберігання і «доставки» користувачеві знань, але при цьому існує ряд
недоліків:
1. При розробці ПЗ та СДН не враховуються потреби та індивідуальні
параметри того, кого навчають. Заданий план навчання поширюється на всіх
студентів однаково, незалежно від навичок і знань конкретного індивіда. Строго
задана траєкторія навчання, заздалегідь поданий певний обсяг освітньої
інформації, не дозволяють врахувати особливості кожного споживача знань, що
істотно відображається на якості освіти.
2. Підтримка та оновлення ПЗ та СДН – шлях дорогий і трудомісткий.
Поява нових знань в предметній галузі неминуче призведе до оновлення всіх
освітніх ресурсів, в яких використовується це знання. Крім того, використання
одних і тих же знань у різних предметних галузях робить вкрай нелегким
підтримку і оновлення освітнього контенту до актуальної версії.
Сьогодні для вирішення перерахованих вище проблем найбільш
доцільним є застосування баз знань, що представляють собою модель або концепцію
зберігання знань. Повноцінні бази знань містять в собі не тільки фактичну
інформацію, але й правила виведення, допускають автоматичні висновки про
нововведені факти і як наслідок, – осмислену обробку інформації.
Ефективним засобом представлення та систематизації знань є
онтології. Онтології використовуються для формальної специфікації понять і
відношень, які характеризують певну галузь знань. Перевагою онтологій як
способу представлення знань є їх формальна структура, яка спрощує комп'ютерну
обробку інформації.
Онтологічний підхід набуває все більшого використання для
найрізноманітніших типів інформаційних систем (ІС) та ЕОР . Про зростаючу роль
онтологій для ІС свідчить також введення в роботі поняття керованих онтологіями
інформаційних систем (Ontology-Driven Information Systems – ODIS). Онтології
можуть використовуватися в ODIS під час їх розробки, використання, інтеграції,
а також можуть підтримувати різні частини інформаційної системи – інтерфейси
користувача, бази даних чи інші компоненти.
КНС, що використовують онтології, знаходять застосування при
розробці та мо-делюванні систем представлення та інтерпретації інформації в
процесі навчання. Онтологія визначає терміни, за допомогою яких можна описати і
структурувати предметну область. Використання онтології ефективне під час
пошуку і об'єднання інформації з різних джерел і середовищ. Мова онтології
використовується для надання інформації чітко визначеного значення і являє
собою загальний набір термінів для опису та подання предметної області, що
вивчається.
Вона використовується як джерело даних для багатьох комп’ютерних
додатків (для інформаційного пошуку, аналізу текстів, вилучення знання),
дозволяючи більш ефективно обробляти складну і різноманітну інформацію.
Вирішальний вплив на функціональні можливості освітнього контенту має модель
даних, яка використовується для представлення знань. Перевагою онтологій в
якості способу представлення знань є їх формальна структура, яка спрощує їх
комп’ютерну обробку.
Таким чином, актуальною є задача створення комп’ютерних навчальних
систем (КНС), заснованих на систематизованих знаннях.
Онтологія – представлення деякою мовою програмування знань про
певну предметну область. Однак, не існує загальноприйнятого визначення
«онтології», різняться погляди і на те, що вони мають включати в себе.
Щодо методів побудови онтологій, то на сьогодні існує ряд мов,
призначених для формального опису онтологій. Серед найбільш відомих і
використовуваних: KIF (Knowledge Interchange Format), DAML+OIL (DARPA Agent
Mark up Language), OWL (Ontology Web Language). Існують також інструментальні
засоби, що підтримують розробку онтологій відповідно до цих специфікацій.
Аналізуючи конструкції даних мов формального опису, можна
помітити, що навіть у найбільш розширеній з них OWL, що включає OIL+DAML,
існують детальні можливості лише для задання класів, підкласів та їх членів (таксономії), для інших же типів
відношень не передбачаються спеціальні елементи – їх можна задавати лише через
властивості класів. На практиці більшість із вже створених онтологій є максимум
ієрархічною структурою понять предметної області. Тобто розробниками
розглядаються лише такі відношення між поняттями, як «вид-клас» та рідше
«об’єкт-атрибут».
Тоді, як у деяких роботах, розроблено класифікацію властивостей
онтологій та уточнено перелік структурних властивостей (таксономічні зв’язки,
композиційні зв’язки, топологічні зв’язки, зв’язки сутностей з процесами,
причинно-наслідкові зв’язки, часові та просторові зв’язки).
Відповідно до концепції Semantic Web створення RDF-описів та
OWL-онтологій покладене на окремих розробників. І на сьогодні, попри досить
незначні напрацювання в плані розробки онтологій, вже виникає проблема
узгодженості онтологій, яка полягає в тому, що різними розробниками для однієї
й тієї ж предметної області можуть бути створені онтології, синтаксично або
семантично гетерогенні, і для їх сумісного використання необхідна трансляція
або відображення (виявлення відповідності між поняттями двох онтологій).
Існує декілька підходів до вирішення проблеми відображення
онтологій, перший з яких – ручне відображення, шляхом встановлення відношень
між концептами, здійснювалося для деяких великих онтологій . Проблема
застосування ручного відображення в тому, що розмір онтологій може бути дуже
великим і продовжуватиме нарощуватися, що вимагатиме надзвичайно багато
людських зусиль для їх відображення. Тому, природно, що дослідники шукають
шляхи відображати онтології автоматично.
Досить значна кількість досліджень, серед яких і, присвячені
розробці засобів відображення онтологій на основі методів машинного навчання,
серед яких особливою популярністю користуються методи класифікації текстів.
Однак результати тут залежать від якості навчальних даних, а підготовка їх
вручну для сотень понять досить складна і дорога, що зменшує привабливість
текстової класифікації.
Ще одним підходом до відображення онтологій є зіставлення імен
понять на основі їх лексичної подібності та використання спеціально розроблених
словників (Word Net), в яких описані відношення між концептами (синонімія) та
властивості ряду концептів.
Альтернативним напрямком досліджень є автоматичне створення
онтологій, яке на сьогодні зводиться до автоматичного анотування текстів у Web.
Аналіз робіт в цьому напрямку подано в, де показано їх обмеження виділенням
певного типу відношень для анотування, або ж використанням для анотування
певної онтології. Результати аналізу пропонується автоматично відображати у OWL
– описи за допомогою OntoSem2OWL.
Розглянемо математичну модель онтології.
Під формальною моделлю онтології О розумітимемо впорядковану
трійку такого вигляду: О = (С, R, F),
де C – скінченна множина
концептів (понять, термінів) предметної області, яку задає онтологія О;
R – скінченна множина відношень між концептами (поняттями, термінами)
заданої предметної області;
F – скінченна множина функцій інтерпретації (аксіоматизація),
заданих на концептах чи відношеннях онтології О.
Зазначимо, що природним обмеженням, що накладається на множину C, є його скінченність і не порожність.
Інша річ з компонентами F і R у визначенні онтології O. Зрозуміло, що і в цьому випадку F і R
мають бути скінченними множинами.
Завдання об’єднання онтологій є найбільш часто вирішуваним при
створенні бази знань КНС. Тому розглянемо більш детально роботу підсистеми
об’єднання онтологій. Онтологія розглядається як граф класів. Кожне поняття є
вершиною, а відносини клас-підклас є дугами. Клас без базового класу є вершиною
графу. Дозволено множинне спадкування. Будемо розглядати онтології, що
представляються єдиним графом понять з однією кореневою вершиною. Граф не має
посилань на зовнішні онтології.
Алгоритм об’єднання онтологій включає наступні укрупнені дії.
1. Вирівнювання порядків онтологій.
2. Розв’язання конфлікту імен.
3. Об’єднання класів та їх властивостей і відносин.
Під порядком онтології розуміється кількість рівнів ієрархії
графу. Пропонований алгоритм може працювати при виконанні двох вимог, які
пред’являються до онтологій, що об’єднуються:
– кількість рівнів ієрархії повинна бути однаковою;
– не повинно бути збігу імен понять, що знаходяться в онтологіях
на різних рівнях ієрархії, тобто повинен бути відсутнім конфлікт імен.
В алгоритмі одна з онтологій вважається базовою, інша – тою, що
доповнює. Алгоритм буде працювати більш ефективно, якщо базова онтологія
більше, ніж та, що доповнює. Імовірність того, що онтології, які об’єднуються,
будуть мати різну ієрархічну структуру, досить велика. Для коректної роботи
запропонованого алгоритму необхідно вирівнювання порядків онтологій.
Вирівнювання порядків – це процес приведення ієрархічної структури онтології з
меншою кількістю рівнів ієрархії до структури другої онтології. Процес реалізується
шляхом додавання в ієрархічну структуру фіктивних рівнів ієрархії. Імена понять
на фіктивних рівнях ієрархії не розглядаються при роботі алгоритму.
Сутність пропонованого алгоритму полягає в наступному.
1. Формування списку збіжних імен понять онтологій, що знаходяться
на різних рівнях ієрархії.
2. Формування списку збіжних імен понять онтологій, що знаходяться
на однакових рівнях ієрархії.
3. Формування списку імен поняття онтології, що доповнює, для яких відсутня синонімічність понять у
базовій онтології на однакових рівнях ієрархії.
Список, отриманий на кроці 1 до початку об’єднання онтологій, має
бути розглянутий експертом з метою розв’язання існуючого конфлікту імен. Тобто
конфлікт імен повинен бути усунений до роботи алгоритму на кроці 2 і 3. На
кроці 2 синонімічні поняття онтологій аналізуються модулем «перевірка
відповідності». На кроці 3 незбіжні поняття обробляються модулем «аналіз
елементів, що не збігаються».
Запропонований алгоритм об’єднання онтологій є важливою складовою
частиною інструментальних засобів інтеграції ЕОР для створення онтологічних баз
знань. Оскільки традиційний підхід до навчання в наш час суттєво потіснили
альтернативні методи навчання, які базуються на інформаційних технологіях.
Сучасні КНС є засобом представлення інформації, засвоєння знань і вмінь, проміжної і підсумкової перевірки. Онтологічний підхід до
створення предметного наповнення ЕОР може бути досить продуктивним, оскільки за
його застосування до змісту навчання кількох
предметів можна отримати абсолютно нове бачення міжпредметних зв’язків.
Ігнорування системних аспектів інженерії програмного забезпечення,
як правило, веде до того, що ПЗ і СДН не відповідають вимогам обраного
обладнання, або не інтегрується іншими системами. Застосування онтологій для
представлення змісту навчальних комп’ютерних дозволить автоматизувати допомогу
викладачам при створенні відповідних навчально-методичних матеріалів.
Завданням подальших розробок і досліджень має бути реалізація
інших складових системи інтеграції, формалізація процесів інтеграції та
розробка більш універсальних алгоритмів розширення онтологій програмного
забезпечення. [15]
Знання – це закономірності предметної області (принципи, закони,
зв’язки), що набуті під час практичної діяльності та професійного досвіду, і в
подальшому дозволяють фахівцям вирішувати задачі в цій області. Отже, знання –
це добре структуровані дані про дані.
Для збереження даних використовують Бази Даних. Вони мають великий
об’єм і відносно невелику вартість зберігання інформації.
Для збереження знань використовують Бази Знань. Тут, характерним є
невеликий об’єм, але дорогі інформаційні масиви. База знань є основою для любої
інтелектуальної системи.
Властивості знань, що відрізняє їх від даних
Внутрішня інтерпретація. Кожна інформаційна одиниця повинна мати
унікальне ім’я, за яким її знаходить інтелектуальна система, а також відповідає
на запитання, де це ім'я згадується.
Структурованість. Знання повинні мати гнучку структуру: одні
інформаційні одиниці можуть міститися у складі інших (клас-ціле, елемент-клас).
Зв’язність. Між різними інформаційними одиницями можуть
встановлюватися різні типи зв’язків (причинно-наслідкові, просторові).
Семантична метрика. Для інформаційних одиниць можна задавати
відношення, що характеризують ситуаційну близькість.
Активність. Виконання програм в інтелектуальній системі повинно
ініціюватися поточним станом бази знань.
Моделі представлення знань
Для використання в системах ШІ знання мають бути формалізовані та
закладені в певну структуру, тобто представлені моделлю знань.
Модель представлення знань – це фіксована система понять і правил,
на підставі якої інтелектуальна система здійснює операції над знаннями.
Моделі представлення знань потрібні для:
· Створення
спеціальних мов опису знань.
· Формалізації
процедур порівняння нових знань з існуючими.
· Формалізації
механізму логічного виведення.
Існує кілька десятків моделей (рис.20) для різних предметних
областей. Більшість з них можна звести до класичних моделей:
· Продукційні
моделі
· Семантичні
сітки
· Фреймові
моделі
· Логічні
моделі
Ці моделі можна розподілити на дві великі групи:
· Модульні
моделі. Оперують окремими, не пов'язаними між собою елементами знань, будь то
правила або аксіоми предметної області.
· Мережні
моделі. Надають можливість пов'язувати елементи або фрагменти знань між собою
через відношення в семантичних сітках або мережах фреймів.
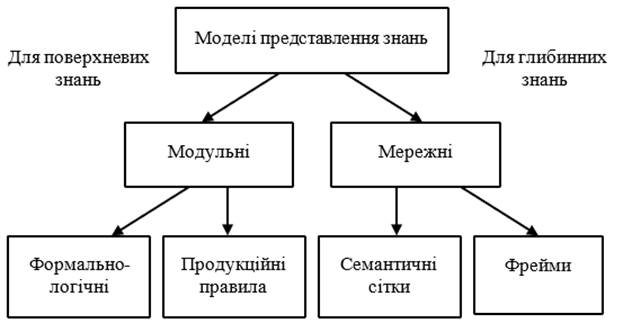
Рисунок 20 – Моделі представлення знань

