Тема 1 Огляд технологій і тенденції роботи з Big Data. Три
принципи роботи з великими даними. Приклади застосування
Питання, що розглядаються: три
принципи роботи з великими даними, методи і техніка аналізу великих даних,
великі дані у промисловості, інструменти опрацювання великих даних
«Великі дані (Big Data) –
позначення структурованих и неструктурованих даних величезних обсягів і
значного розмаїття, що піддаються ефективній обробці програмних інструментів,
які горизонтально масштабуються та з’явились у кінці 2000-х років, і
альтернативних традиційних систем управління базами даних і рішенням класу
рішень Business Intelligence» [1, 2].
До цього визначення Вікіпедія додає наступне: «в широкому сенсі
про «великі дані» говорять, як про соціально-економічний феномен, пов’язаний з
появою технологічних можливостей аналізувати величезні масиви інформації, у
деяких проблемних галузях – весь світовий об’єм даних, і трансформаційні
наслідки, які з цього випливають». Можна користуватись і більш простим
визначенням, яке цілком відповідає усталеним і більш простим визначенням, що
цілком відповідають думці журналістів і маркетологів. «Великі дані – це сукупність
технологій, покликаних здійснювати три операції:
1. Обробляти більші, у порівнянні зі «стандартними» сценаріями,
об’єми даних.
2. Уміти працювати з даними, що швидко надходять у дуже великих
об’ємах. Тобто даних не просто багато, а їх постійно стає все більше й більше.
3. Вміти працювати зі структурованими і неструктурованими даними паралельно і у різних аспектах».
Три
"V" (4, 5, 7) і три принципи роботи з великими даними
Визначальними
характеристиками для великих даних є, крім їх фізичного об’єму, й інші, які
підкреслюють складність задачі обробки і аналізу цих даних. Набір даних VVV
(volume, velocity, variety — фізичний об’єм, швидкість приросту даних і
необхідність їх швидкої обробки, здатність обробляти дані різних типів) був
розроблений компанією Meta Group у 2001 році з метою вказати на рівну
значимість управління даними по всім трьом аспектам.
У
подальшому з’явилась інтерпретація з чотирма V (додалась veracity –
достовірність), п’ятю V (viability – життєздатність і value – цінність), семи V
(variability – змінність та visualization – візуалізація). Але компанія IDC,
наприклад, інтерпретує саме четверте V як value (цінність), підкреслюючи
економічну доцільність обробки великих об’ємів даних у відповідних умовах.
Виходячи з вищеназваних визначень, основні принципи роботи з великими даними
такі:
−
Горизонтальна масштабованість. Це − базовий принцип обробки великих даних. Як вже було зазначено,
великих даних з кожним днем стає все більше. Відповідно, необхідно збільшувати
кількість обчислювальних вузлів, за якими розподіляються ці дані, при чому
обробка має відбуватись без погіршення продуктивності
−
Відмовостійкість. Цей принцип
витікає з попереднього. Оскільки обчислювальних вузлів у кластері може бути
багато (іноді десятки тисяч) та їх кількість, не виключено, буде збільшуватись,
зростає ймовірність виходу машин з ладу. Методи роботи з великими даними мають
враховувати ймовірність таких ситуацій і передбачати превентивні заходи
−
Локальність даних. Оскільки дані
розподілені по великій кількості обчислювальних вузлів, то, якщо вони фізично
знаходяться на одному сервері, а обробляються на іншому, витрати на передачу
даних можуть бути невиправдано великими. Тому обробку даних бажано проводити на
тій же машині, на якій вони зберігаються
Ці принципи відрізняються від тих, які характерні для традиційних,
централізованих, вертикальних моделей зберігання добре структурованих даних.
Власне, для роботи з великими даними розробляються підходи і технології.
Технології
і тенденції роботи з Big Data
Початково
у сукупність підходів і технологій включались засоби масової-паралельної
обробки невизначено-структурованих даних, такі як СУБД NoSQL, алгоритми
MapReduce і засоби проекту Hadoop. У подальшому до технологій великих даних
почали відносити й інші рішення, що забезпечують схожі за характеристиками
можливості обробки надвеликих масивів даних, а також деякі апаратні засоби.
−
MapReduce — модель розподілених обчислень
у комп’ютерних кластерах, представлена компанією Google. Згідно з цією моделлю,
додаток розділяється на значну кількість однакових елементарних завдань, що
виконуються на вузлах кластера і потім, природнім шляхом зводяться у кінцевий
результат.
−
NoSQL (від англ. Not Only SQL, не
лише SQL) — загальний термін для різних нереляційних баз даних і сховищ, не
означає якусь конкретну технологію чи продукт. Звичайні реляційні бази даних
добре підходять для досить швидких і однотипних запитів, а на складних і гнучко
побудованих запитах, характерних для великих даних, навантаження перевищує
розумні межі і використання СУБД стає неефективним.
−
Hadoop — набор утилітів, бібліотек
і фреймворків, що вільно розповсюджується, для розробки і виконання
розподілених програм, які працюють на кластерах із сотень і тисяч вузлів.
Вважається однією з основоположних технологій більшості даних.
−
R — мова програмування для
статистичної обробки даних і роботи з графікою. Широко використовується для
аналізу даних і фактично став стандартом для статистичних програм.
−
Апаратні рішення. Корпорації
Teradata, EMC та ін. др. пропонують апаратно-програмні комплекси, призначені
для обробки великих даних. Ці комплекси поставляються як готові до установки
телекомунікаційні шафи, що містять кластер серверів і керівне програмне
забезпечення для масово-паралельної обробки. Сюди іноді відносять апаратні
рішення для аналітичної обробки в оперативній пам’яті, зокрема,
апаратно-програмні комплекси Hana компанії SAP і комплекс Exalytics компанії
Oracle, незважаючи на те, що така обробка початково не є масово-паралельною, а
об’єми оперативної пам’яті одного вузла обмежуються кількома терабайтами.
Консалтингова компанія McKinsey, окрім технологій NoSQL,
MapReduce, Hadoop, R, які розглядає більшість аналітиків, включає у контекст
придатності для обробки великих даних також технології Business Intelligence і
реляційні системи управління базами даних з підтримкою мови SQL.
Методи і техніка аналізу великих даних
Міжнародна консалтингова компанія McKinsey, що спеціалізується на
розв’язанні задач, пов’язаних зі стратегічним управлінням, виділяє 11 методів і
технік аналізу, що застосовуються до великих даних.
−
Методи класу Data Mining (видобуток
даних, інтелектуальний аналіз даних, глибинний аналіз даних) — сукупність
методів виявлення у даних раніше невідомих, нетривіальних, практично корисних
знань, необхідних для прийняття рішень. До таких методів, зокрема, належать:
навчання асоціативним правилам (association rule learning), класифікація (розгалуження
на категорії), кластерний аналіз, регресійний аналіз, виявлення і аналіз
відхилень тощо.
−
Краудсорсинг — класифікація і
збагачення даних силами широкого, неозначеного кола особистостей, що виконують
цю роботу без вступу у трудові стосунки.
−
Злиття та
інтеграція даних (data fusion and integration) — набір технік, що дозволяють
інтегрувати різнорідні дані з розмаїття джерел з метою проведення глибинного
аналізу (наприклад, цифрова обробка сигналів, обробка природної мови, включно з
тональним аналізом).
−
Машинне навчання, включаючи
навчання з учителем і без учителя – використання моделей, побудованих на базі
статистичного аналізу машинного навчання для отримання комплексних прогнозів на
основі базових моделей.
−
Штучні нейронні мережі, мережевий
аналіз, оптимізація, у тому числі генетичні алгоритми (genetic algorithm —
евристичні алгоритми пошуку, що використовуються для розв’язання задач
оптимізації і моделювання шляхом випадкового підбору, комбінування і варіації
потрібних параметрів з використанням механізмів, аналогічних натуральному
відбору у природі)
−
Розпізнавання образів
−
Прогнозна аналітика
−
Імітаційне моделювання (simulation)
— метод, що дозволяє будувати моделі, що описують процеси так, як вони би
проходили у дійсності. Імітаційне моделювання можна розглядати як різновид
експериментальних випробувань.
−
Просторовий аналіз (spatial
analysis) — клас методів, що використовують топологічну, геометричну і
географічну інформацію, що вилучається із даних.
−
Статистичний аналіз — аналіз
часових рядів, A/B-тестування (A/B testing, split testing — метод
маркетингового дослідження; при його використанні контрольна група елементів
порівнюється із набором тестових груп, у яких один чи кілька показників були
змінені, щоб з’ясувати, які зі змін покращують цільовий показник.
−
Візуалізація аналітичних даних —
подання інформації у вигляді малюнків, діаграм, з використанням інтерактивних
можливостей і анімації, як для отримання результатів, так і для використання у
якості вихідних даних для подальшого аналізу. Дуже важливий етап аналізу
великих даних, що дозволяє показати найважливіші результати аналізу у найбільш
зручному для сприйняття вигляді.
Великі дані у промисловості
Згідно звіту компанії McKinsey «Global Institute, Big data: The
next frontier for innovation, competition, and productivity», дані стали таким
само важливим фактором виробництва, як трудові ресурси чи виробничі активи. За
рахунок використання великих даних, компанії можуть отримувати відчутні
конкурентні переваги. Технології Big Data можуть бути корисними при вирішенні
наступних задач:
−
прогнозування ринкової ситуації
−
маркетинг і оптимізація продажів
−
вдосконалення продукції
−
ухвалення управлінських рішень
−
підвищення продуктивності праці
−
ефективна логістика
−
моніторинг стану основних фондів.
На виробничих підприємствах великі дані генеруються також
внаслідок впровадження підприємства, великі дані генеруються також внаслідок
впровадження технологій Промислового інтернету речей. У ході цього процесу
основні вузли і деталі станків і машин оснащуються датчиками, виконавчими
пристроями, контролерами та, іноді, недорогими процесорами, здатними виробляти
граничні (туманні) обчислення. В процесі виробничого процесу здійснюється
постійний збір даних і, можливо, їх попередня обробка (наприклад, фільтрація).
Аналітичні платформи обробляють результати у найбільш зручному для сприйняття
вигляді і зберігають для подальшого використання. На основі аналізу отриманих
даних робляться висновки про стан обладнання, ефективність внесених змін у
технологічні процеси і т.д..
Завдяки моніторингу інформації у режимі реального часу персонал
підприємства має змогу:
−
скорочувати кількість простоїв
−
підвищувати продуктивність
обладнання
−
зменшувати витрати на експлуатацію
обладнання
−
запобігати нещасним випадкам.
Крім того, за результатами аналізу великих даних можна розрахувати строки окупності обладнання,
перспективи змін технологічних режимів, скорочення обслуговуючого персоналу –
тобто приймати стратегічні рішеня стосовно подальшого розвитку підприємства.
Інструменти опрацювання Великих даних
На рисунку 1 подано відомості щодо ряду інструментів опрацювання
Великих даних з відкритим вихідним кодом, які надаються через інфраструктури
хмарних обчислень. Більшість інструментів забезпечується Apache і випущені під
ліцензією Apache. Усі ці продукти згруповано за типами задач, що виникають в
процесах опрацювання Великих даних.
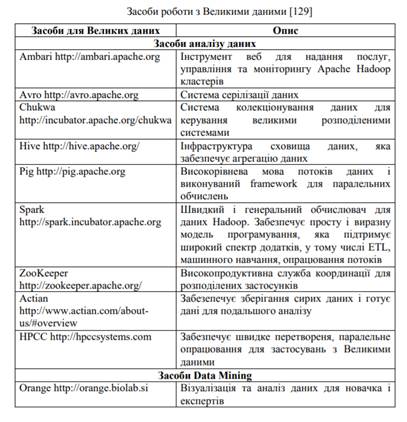
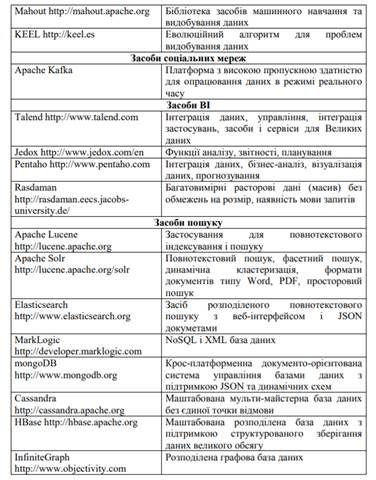
Рисунок 1

