ЛАБОРАТОРНА РОБОТА №5.
Тема. Кластерний аналіз з
використанням пакету статистичного аналізу даних Statistica.
Мета:
Закріплення теоретичного матеріалу за темою «Використання пакету
статистичного аналізу даних Statistica для прийняття управлінських
рішень». Набуття практичних навичок
роботи в модулі Cluster Analysis
пакету Statistica.
Завдання:
1.
Побудувати моделі класифікації підприємств, використовуючи метод К-середніх в модулі Cluster Analysis ППП Statistica.
2.
Зробити висновки.
Хід роботи.
1. Обрати для дослідження об’єкти (підприємства певної
галузі) і показники (наприклад, х1
– продуктивність праці, х2 – рентабельність капіталу, х3 – фондовіддача).
Сформувати таблицю даних.
2. Вибрати модуль Cluster Analysis ,
для чого слід ввійти в позицію меню Statistics / Multivariate Exploratory Techniques / Cluster
Analysis. Підтвердити вибір цього модуля.
3. На стартовій панелі модуля вибрати напрям аналізу,
тобто метод класифікації: Joining tree clustering (деревоподібна кластеризація); K-means clustering (метод k-середніх); Two-way joining (двовходова
кластеризація).
4. Вибрати метод K-means clustering (метод K-середніх), підвердити свій вибір, після чого слід задати параметри для
проведення кластеризації: Variable (Змінні), Cluster (Об’єкти кластеризації), Number of clusters (кількість кластерів), Number of iterations (кількість ітерацій), Initial cluster centers (початкові центри кластерів) (рис. 5.1).
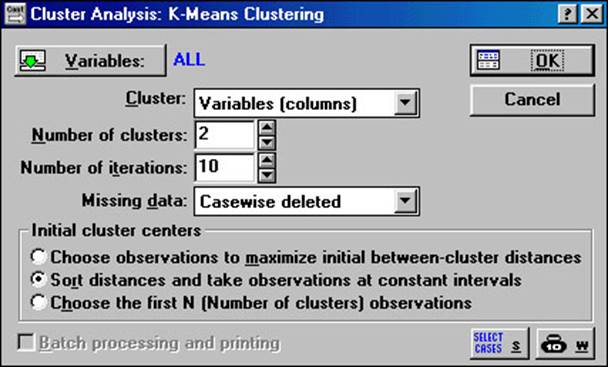
Рис. 5.1. Вікно Cluster Analysis: K-means clustering (метод K-середніх)
Кнопка Variables дозволяє вибрати змінні беруть участь у класифікації. Натиснемо на кнопку Variables і виберемо всі змінні Select All.
У рядку Cluster вказується як ведеться класифікація: при запуску встановлено
режим Variables (colums) – класифікуються змінні на підставі їхніх спостережень, однак у
переважній більшості випадків використовується режим Cases (rows) – класифікуються спостереження. Для того щоб включити режим Cases (rows), треба натиснути на кнопку у кінці рядка, після чого у віконці,
підвести курсор на напис Cases (rows) і натиснути ліву кнопку
У рядку Number of iterations вказується кількість ітерацій в розрахунках кластерів.
Як правило, встановлених за
замовчуванням 10
ітерацій
цілком
достатньо.
У рядку Missing data встановлюється режим роботи з тими спостереженнями (або
змінними, якщо
встановлено режим
Variables (columns) у рядку Cluster) в яких пропущені дані. Якщо встановити
режим
Subsituted by means (Замінювати
на середнє),
то замість
пропущеного
числа
буде
використано
середнє
по цій змінній (або спостереженню). Переключення
в режим
Subsitituted by means виконується аналогічно
перемикання в рядку Cluster.
Після
відповідного вибору
натиснемо
кнопку OK. Будуть проведені
обчислення
і з’явиться нове вікно:
«K-Means Clustering
Results» (рис. 5.2).
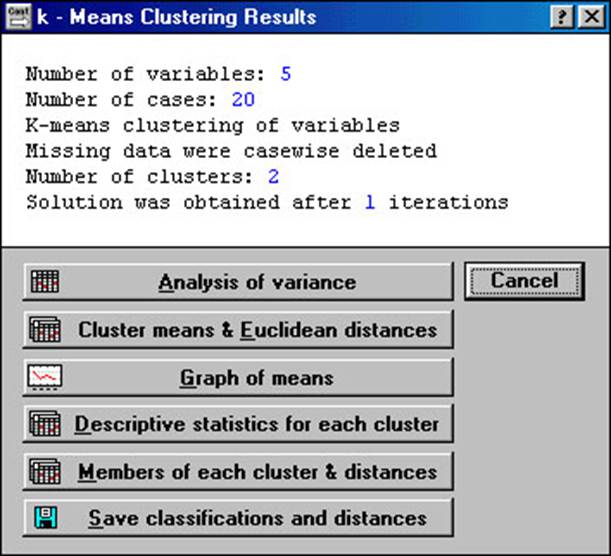
Рис. 5.2. Результати застосування
методу «K-Means Clustering Results»
Висновок за результатами та їх
аналіз.
У верхній частині вікна (у тому ж порядку,
як вони йдуть на екрані):
• Кількість змінних.
• Кількість спостережень.
• Класифікація спостережень (або змінних, залежить від установки в попередньому вікні в рядку Cluster) методом K-середніх.
• Спостереження з пропущеними даними видаляються (або: змінюються середніми значеннями. Залежить від установки в попередньому вікні в рядку Missing data).
• Кількість кластерів.
• Розв’язок отримано після: кількість ітерацій.
5. У вікні аналізу результатів у верхній частині буде
основна інформація та обрані процедури дослідження, у нижній частині вікна на
вкладці Advanced опції, призначені для аналізу результатів кластеризації: Summary: Cluster means & Euclidean distances (евклідові відстані та
середні значення станів кластерів); Analysis of variance (дисперсійний аналіз); Graf of means (графік середніх значень); Descriptive statistics for each cluster (описові статистики для
кластерів); Members of each cluster & distances (члени кластерів та їх
відстані до центру кластера); Save classifications and distances (збереження результатів кластерізації).
6. Ініціювавши
клавішу Summary: Cluster means & Euclidean distances, отримаємо евклідові
відстані та середні значення станів кластерів. Під головною діагоналлю матриці знаходяться значення евклідових
вістаней, а над головною діагоналлю – квадрат еквклідових відстаней (рис.
5.3).

Рис. 5.3. Евклідова
відстань у кластерах.
У таблиці (рис.
5.3) наведені відстані між
класами.
І по вертикалі, і по горизонталі
вказані
номери
кластерів. Таким чином при перетині
рядків
і стовпців
вказані
відстані
між
відповідними
класами.
Причому
вище
діагоналі
(на якій
стоять
нулі)
вказані
квадрати,
а нижче
просто
евклідова відстань.
7. Ініціювавши
клавішу Graf of means, отримаємо графік середніх значень для
кластерів станів (рис. 5.4).
Graph of means представляє собою
графічне
зображення
інформації, яка міститься
в таблиці, що виводиться
при натисканні
кнопки
Analysis of Variance (аналіз дисперсії). На графіку показані середні значення змінних для кожного кластера.
По горизонталі відкладені
змінні, що приймають участь в класифікації,
а по вертикалі – середні значення змінних у розрізі одержуваних кластерів.
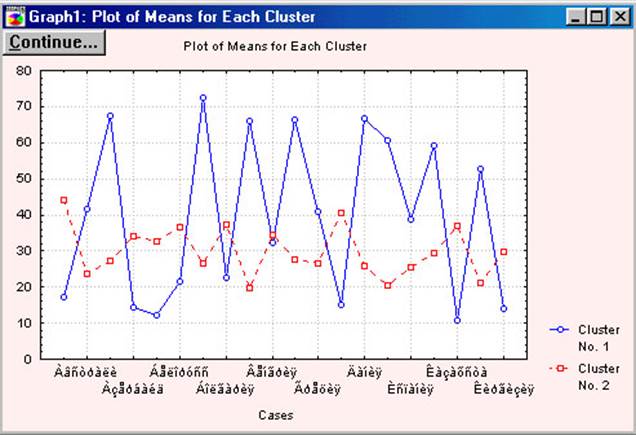
Рис. 5.4. Графічне зображення середньої відстані між кластерами.
8. Ініціювавши
клавішу Analysis of variance, отримаємо результати дисперсійного аналізу оцінки якості
показників у вигляді таблиці, в якій наведені значення міжгрупових
і внутрішньогрупових дисперсій
признаків. Чим менше значення внутрішньогрупової дисперсії і більше значення міжгрупової, тим краще ознака характеризує
приналежність об’єктів до
кластера. Параметри F
і p визначають
внесок ознаки в класифікацію (рис. 5.5).

Рис. 5.5. Analysis of
Variance (аналіз дисперсії).
В рядках – змінні (спостереження), в стовпчиках – показники для кожної змінної: дисперсія між кластерами, число ступенів свободи для міжкласової дисперсії, дисперсія всередині кластерів, число ступенів свободи для внутрікласової дисперсії, F - критерій, для перевірки гіпотези про нерівність дисперсій.
9. Ініціювавши
клавішу Descriptive statistics for each cluster, отримаємо описові статистики для виділених кластерів, а саме:
середнє, середньоквадратичне відхилення та дисперсія.
10. Ініціювавши клавішу Members of each cluster & distances, отримаємо члени кластерів
та їх відстані до центру відповідного кластеру у вигляді таблиці, дані якої
дозволяють визначити склад кожного кластеру.
11. Save classifications and distances дозволяє зберегти у форматі програми статистика таблицю, в якій
містяться значення всіх змінних, їх порядкові номери, номери кластерів до яких
вони віднесені, і евклідові відстані від центру кластера до спостереження. Записана таблиця може
бути викликана будь-яким
блоком або піддана подальшій обробці
12. Зробити висновки та подати економічну інтерпретацію отриманих результатів кластерних утворень.
Література: [4; 22].
![]()
![]()