ТЕМА 4. СТАТИСТИЧНІ МЕТОДИ АНАЛІЗУ ВЕЛИКИХ МАСИВІВ ДАНИХ.
1. Зміст та
характеристики великих масивів даних – Big Data.
2. Методи
і технології аналізу та візуалізації великих масивів даних.
3. Особливості обробки багатомірних статистичних даних.
Методи багатовимірної класифікації.
4. Кластерний
аналіз.
5. Дискримінантний аналіз.
1. Зміст та характеристики
великих масивів даних – Big Data.
Big Data (великі дані) –
це величезні обсяги неоднорідної, неструктурованої або слабо структурованої,
істотно розподіленої і інтенсивно зростаючої цифрової інформації, що
змінюється, яку неможливо обробити традиційними засобами. А також методи,
технології і засоби їх збору, зберігання, обробки і аналізу з метою отримання
результатів, що сприймаються людиною
Вперше у 2001
році для Big Data були сформульовані визначальні характеристики: об’єм,
швидкість, різноманітність («3V»); достовірність і цінність (значимість) («5V»); мінливість і
волативність (актуальність) («7V»); врахливість, придатність (обгрунтованість) і візуалізація
(«10V»).
Volume (об’єм). Вважається, що Big Data починаються з
обсягів в петабайт (1024 терабайт). Big Data з’являються
тоді, коли сотні мільйонів людей об’єднуються в співтовариства та викладають
свої інформаційні ресурси, або об’єднані центри наукових досліджень надають
дані результатів своїх досліджень
Velocity (швидкість) є однією з важливих характеристик Big Data з точки зору їх
практичного використання. Під швидкістю розуміється як швидкість приросту
(надходження, накопичення) даних, так і швидкість їх обробки з метою отримання
кінцевих результатів. Крім
того, в цю категорію включаються характеристики інтенсивності та обсягів
інформаційних потоків. Для цього технологія обробки таких даних повинна
допускати можливість їх аналізу вже в момент їх породження (іноді
її називають «оперативною аналітикою»), тобто до того, як вони потраплять в
сховище даних.
За словами фахівців, до категорії Big Data відноситься
більшість потоків даних понад 100 Гб в день.
Variety (різноманітність). Можливість
сприймати, зберігати та обробляти різні дані. Говорячи про різноманіття, мається на увазі наступне.
1. Різні джерела отримання даних.
2. Різні способи представлення даних.
3. Різні формати зберігання (надходження)
даних. Це можуть бути тексти,
аудіо- і відео дані, зображення. Більш того, одні й ті ж дані можуть
бути представлені в різних форматах.
4. Семантична різноманітність.
5. Різна ступінь структурованості даних. Традиційні бази даних дозволяють зберігати структуровані
дані, але фактично в даний час породжувані дані на 80 % є слабо
структурованими або навіть неструктурованими.
Технологія Big Data дозволяє об’єднувати та обробляти
дані, що володіють наведеним вище різноманіттям
Veracity (достовірність). Властивість, яка
характеризує надійність даних. Технологія створення і використання традиційних
баз даних (БД) передбачає, що в БД надходять ретельно відібрані та перевірені
дані. У Big Data вихідні дані можуть бути «сирими», тобто
надходять без будь-якої попередньої обробки, вони можуть бути
суб’єктивними, випадковими та містити багато «шуму». Ще один
критерій цієї характеристики – ступінь довіри до даних, що надходять.
Хоча Big Data надають прекрасні можливості для аналізу і
прийняття рішень, однак їх цінність багато в чому залежить від
якості вихідних даних. Технологія Big Data враховує цю
характеристику та дозволяє надійно працювати з такими даними
Value (цінність). Коли йде мова про цінності
даних, то мається на увазі їхня соціальна значимість з точки
зору прикладних задач. За розрахунками IBS, тільки 1,5%
накопичених масивів даних має інформаційну значимість. Велика кількість
даних – це добре, але якщо дані не становлять жодного інтересу,
то вони не приносять користі.
Variability (мінливість). Під мінливістю Big Data мається на
увазі ситуація, коли постійно змінюється сенс даних. Наприклад, це має місце,
коли збір і обробка даних відбувається в процесі аналізу тестів і
особливо при перекладі з однієї мови на іншу.
Volatility (волатильність, актуальність) –
характеристика, яка визначає, який період часу старіння даних,
коли вони стають нерелевантними або марними. Як довго їх
треба зберігати? До ери Big Data дані могли зберігатися невизначено
довго, використання для цих цілей декілька десятків терабайт не
було обтяжливим. Більш того, їх можна було зберігати в
чинній базі даних, не викликаючи при цьому проблем з ресурсами.
Однак при наявності Big Data, враховуючи характеристики обсягу
і швидкості, слід ретельно стежити за волатильністю даних.
Необхідно встановити правила управління зберіганням даних з тим,
щоб забезпечити ефективне їх використання.
Vulnerability (вразливість). Великі дані породжують нові проблеми їх безпеки.
Злом великих даних призводить до великого зламу в цілому.
Validity (придатність, обґрунтованість)
тісно пов’язана з достовірністю і характеризує, якою мірою наявні дані є
точними і правильними з точки зору їх передбачуваного використання.
Visualization (візуалізація). Після отримання та обробки
даних їх треба представити таким чином, щоб вони
були читабельними та доступними. Саме це і має на увазі
візуалізація.
Класифікація Big Data, яка дозволяє співвіднести технологію з результатом,
який чекають від обробки Big Data:
- швидкі дані (Fast Data), їх об`єм вимірюється терабайтами-петабайтними;
- велика аналітика (Big Analytics) – петабайтні-екзабайтні дані;
- глибоке проникнення (Deep Insight) – екзабайти-зеттабайти.
Групи розрізняються між собою не тільки оперованими обсягами
даних, але й якістю рішення задач з їх обробки.
Обробка для Fast Data не передбачає
отримання нових знань, її результати співвідносяться з апріорними знаннями та
дозволяють судити про те, як протікають ті чи інші процеси, вона дає можливість
краще й детальніше побачити те, що відбувається, підтвердити або відкинути
якісь гіпотези. Тільки
невелика частина з існуючих технологій підходить для
вирішення завдань Fast Data. В цей список потрапляють деякі технології
роботи зі сховищами. Швидкість роботи цих технологій має
зростати синхронно із зростанням обсягів даних.
Завдання, які
вирішуються засобами Big Analytics, помітно відрізняються, причому не тільки кількісно, але і
якісно, а відповідні технології повинні допомагати в отриманні нових знань –
вони служать для перетворення зафіксованої в даних інформації в нове знання. Однак на цьому середньому рівні не
передбачається наявність штучного інтелекту при виборі
рішень або будь-яких автономних дій аналітичної системи – вона
будується за принципом «навчання з учителем». Інакше кажучи, весь її аналітичний потенціал
закладається в неї в процесі навчання.
Вищий рівень, Deep Insight, передбачає навчання без
вчителя та використання сучасних методів аналітики, а
також різні способи візуалізації. На цьому рівні можливе
виявлення знань і закономірностей, апріорно невідомих.
Основні принципи роботи з великими даними:
1. Розподільність. Зберігати інформацію в одному місці
безглуздо і практично неможливо. Тому технологія роботи з Big Data повинна
використовувати розподілене зберігання, управління, обробку та аналіз даних, що
знаходяться в різноманітних сховищах даних у всьому світі.
2. Горизонтальна масштабованість. Оскільки даних може
бути як завгодно багато – будь-яка система, яка має на увазі обробку великих
даних, повинна бути розширюваною. У 2 рази зріс обсяг даних – в 2 рази
збільшили кластер і все продовжило працювати з такою ж продуктивністю.
3. Відмовостійкість. Принцип горизонтальної
масштабованості має на увазі, що машин в кластері може бути багато. Наприклад,
Hadoop-кластер Yahoo має більш ніж 42000 машин. Це означає, що частина цих
машин буде гарантовано виходити з ладу. Методи роботи з великими даними повинні
враховувати можливість таких збоїв і переживати їх без будь-яких значущих
наслідків.
4. Локальність даних. У великих розподілених системах дані
розподілені по великій кількості машин. Якщо дані фізично знаходяться на одному
сервері, а обробляються на іншому, витрати на передачу даних можуть перевищити
витрати на саму обробку. Тому одним з найважливіших принципів проектування
BigData-рішень є принцип локальності даних – по можливості обробляємо дані на
тій же машині, на якій вони зберігаються.
5. Інтерпретація даних в процесі їх обробки. Дані
надходять до сховища такими, як є, без будь-якого їх попереднього опису, без
зазначення їх структури і семантики. І тільки в процесі їх вибірки для обробки
відбувається їх «осмислення».
Всі сучасні засоби роботи з великими даними так чи інакше
слідують цим п’ятьом принципам.
2.
Методи і технології
аналізу та візуалізації великих масивів даних.
До теперішнього
часу створено та адаптовано безліч методів і технологій для збору, агрегування,
маніпулювання, аналізу і візуалізації великих даних. Ці методи і технології запозичені з різних
областей, включаючи статистику, інформатику, прикладну математику та
економіку. Це означає, що для отримання вигоди з великих
даних, слід використовувати гнучкий міждисциплінарний підхід.
Деякі методи і технології були розроблені для оперування значно
меншими обсягами і різноманітністю даних, але були успішно
адаптовані для Big Data. Інші були розроблені останнім часом,
зокрема, для збору і аналізу великих даних.
Методи аналізу великих даних можна поділити за групами:
− навчання асоціативним правилам – метод, який
базується на правилах, що використовуються для навчання
машин способам виявлення залежностей між даними у базах
великих даних;
− класифікація – методи категоризації нових даних
на основі принципів, раніше застосованих до вже
наявних даних;
− кластерний аналіз – статистичний метод
класифікації об’єктів, який призводить до поділу різноманітних груп на більш
дрібні групи подібних (схожих) об’єктів, для яких критерій подібності заздалегідь
не відомий;
− регресійний аналіз.
1. Краудсорсінг
(Crowdsourcing) – метод збору, категоризація та збагачення даних силами
широкого кола осіб, залучених на підставі публічної оферти, без вступу в
трудові відносини, зазвичай за допомогою використання мережевих медіа.
2. Змішання та
інтеграція даних (Data Fusion and Integration) – набір методів, що дозволяють інтегрувати і аналізувати різнорідні
дані з різноманітних джерел для глибинного аналізу більш точно і ефективно, ніж
з єдиного джерела даних. Як приклади методів цього класу є цифрова обробка сигналів і
обробка природної мови.
3. Навчання асоціативним правилами (Аssociation Rule Learning)
– сукупність методів для аналізу необхідних взаємозв’язків, тобто «асоціативних
правил», серед змінних в великих базах даних.
4. Машинне навчання (Machine Learning) – клас методів
штучного інтелекту, характерною рисою яких є не пряме рішення задачі, а навчання в
процесі застосування рішень безлічі подібних завдань. Включає
навчання з учителем і без вчителя, а також використання моделей,
побудованих на базі статистичного аналізу або машинного навчання, для отримання
комплексних прогнозів на основі базових моделей.
5. Обробка природної мови (Natural Language Processing,
NLP) – загальний напрямок штучного інтелекту та математичної лінгвістики, який
вивчає проблеми комп’ютерного аналізу і синтезу природних
мов. Стосовно до штучного інтелекту аналіз означає розуміння
мови, а синтез – генерацію грамотного тексту. Багато NLP-методів
є методами машинного навчання.
6. Штучні нейронні мережі (Artificial Neural Networks) –
математична модель, побудована за принципом організації та функціонування
біологічних нейронних мереж – мереж нервових клітин живого
організму.
7. Мережевий аналіз (Network Analysis) – набір методів,
використовуваних для опису і аналізу відносин між дискретними вузлами в
графі або мережі. В соціальній мережі аналізуються зв’язки між
людьми в суспільстві або організації, наприклад, як переміщається
інформація або хто має найбільший вплив на кого.
8. Розпізнавання образів (Pattern Recognition) – набір
методів машинного навчання, які розвиваюті основи і
методи класифікації та ідентифікації предметів, явищ, процесів,
сигналів, ситуацій, об’єктів, що характеризуються кінцевим
набором деяких властивостей і ознак.
9. Прогнозна аналітика (Predictive Analytics) – клас
методів аналізу даних, концентруючись на
прогнозуванні майбутньої поведінки об’єктів і суб’єктів з метою
прийняття оптимальних рішень.
10. Аналіз тональності тексту (Sentiment Analysis). Клас методів контент-аналізу в комп’ютерній лінгвістиці, призначений для автоматизованого виявлення в текстах емоційно забарвленої лексики і емоційної оцінки авторів (думок) по відношенню до об’єктів, мова про які йде в тексті.
11. Імітаційне моделювання (Simulation Modeling) – метод дослідження, при якому система, що вивчається, замінюється моделлю, з достатньою точністю описує реальну систему (побудована модель описує процеси так, як вони проходили б у дійсності), з якої проводяться експерименти, з метою отримання інформації про цю систему.
12. Просторовий аналіз (Spatial Analysis) – набір методів, які аналізують топологічні, геометричні або географічні властивості, представлені в наборі даних. Часто дані
для просторового аналізу надходять з географічних інформаційних
систем.
13. А/В
тестування (A/B Testing) – контрольна група елементів порівнюється з набором тестових
груп, в яких один або кілька показників були змінені для того, щоб з’ясувати,
які зі змін покращують цільовий показник.
14. Аналіз
часових рядів (Time Series Analysis) – сукупність математично-статистичних методів аналізу,
призначених для виявлення структури часових рядів і для їх прогнозування. Сюди
відносяться, зокрема, методи регресійного аналізу. Виявлення структури
часового ряду, необхідної, щоб побудувати математичну модель того
явища, яке є джерелом аналізованого часового ряду.
Аналіз великих обсягів даних потребує методів обробки, які
виходять за межі традиційних статистичних методів. Виділяють такі групи методів
аналітики Великих даних:
1) методи Data Mining – методи інтелектуального аналізу даних, застосування яких
дозволяє розв’язати такі задачі: класифікація (Classification); кластеризація (Clustering); асоціація (Associations);
послідовність (Sequence), або послідовна асоціація (sequential association); прогнозування (Forecasting); визначення відхилень (Deviation Detection), аналіз відхилень або викидів; оцінювання (Estimation); аналіз
зв’язків (Link Analysis); візуалізація (Visualization, Graph Mining); підбивання
підсумків (Summarization) – опис конкретних груп об’єктів за допомогою аналізованого
набору даних;
2) технології Text Mining – набір методів, які призначені для видобування відомостей з
текстів на основі сучасних ІКТ, що дає змогу виявити закономірності, які
забезпечують користувачам отримання корисних даних та нових знань. Основна мета Text Mining – надати аналітику можливість
працювати з великими обсягами початкових даних за рахунок автоматизації процесу здобуття
потрібних даних. Основними методами технології Text Mining є: класифікація
(classification); кластеризація (clustering); побудова семантичних мереж або аналіз
зв’язків (Relationship, Event and Fact Extraction); здобуття феноменів, фактів, понять (feature extraction); автоматичне реферування, створення анотацій (summarization);
відповідь на запити (question answering); тематичне індексування (thematic indexing); пошук за ключовими словами (keyword searching); засоби підтримки та створення таксономії (oftaxonomies) і
тезаурусів (thesauri);
3) технологія
MapReduce – підхід і шаблон проведення обчислювальних алгоритмів, який полягає
у створенні карти (map) виконаних обчислювальних алгоритмів і відстежуватнні локальних
результатів, а потім акумулюванні результати (reduced). це фреймворк
для обчислення деяких наборів розподілених завдань з використанням великої
кількості комп’ютерів (“нод”), що утворюють кластер. Опрацьовуватися можуть дані, які
зберігаються або в файловій системі (неструктуровано), або в базі даних
(структуровано);
4) візуалізація
даних – методи графічного подання результатів аналізу великих даних у вигляді
діаграм або анімації для спрощення інтерпретації, полегшення розуміння
отриманих результатів. Візуалізація аналітичних даних – зображення інформації у
вигляді рисунків, графіків, схем і діаграм з використанням інтерактивних
можливостей та анімації для результатів, а також вихідних даних для подальшого
аналізу. Наочне представлення результатів аналізу Великих даних має принципове
значення для їхньої інтерпретації. Сприйняття людини обмежене, і вчені
продовжують вести дослідження у галузі вдосконалення сучасних методів подання
даних у вигляді зображень, діаграм або анімацій. Новими прогресивними методами візуалізації
є: хмара тегів; кластерограма; історичний потік; просторовий
потік;
5) інші
технології та методики аналізу:
- оптимізація (Optimization) – набір числових методів для редизайну
складних систем і процесів для поліпшення одного або декількох показників. Допомагає у прийнятті стратегічних рішень,
наприклад, складу виведеної на ринок продуктової лінійки, у проведенні
інвестиційного аналізу тощо.
-
прогнозне моделювання (Predictive Modeling)
– набір методик, які дають змогу створити математичну модель наперед заданого
ймовірного сценарію розвитку подій;
-
статистика (Statistics) – наука про
збирання, організацію та інтерпретацію даних, зокрема розроблення опитувальників
і проведення експериментів. Статистичні методи часто застосовують для оцінкових
суджень про взаємозв’язки між тими чи іншими подіями;
-
моделювання (Simulation) – моделювання
поведінки складних систем часто використовується для прогнозування,
передбачення і опрацювання різних сценаріїв під час планування;
-
злиття та інтеграція даних (Data Fusion and
Data Integration) – набір технік, що дають змогу інтегрувати різнорідні дані з
різноманітних джерел інформації для проведення глибинного аналізу. Цей набір
методик дає змогу аналізувати коментарі користувачів соціальних мереж і
зіставляти з результатами продажів у режимі реального часу.
Існує безліч технологій для
агрегації, маніпулювання, управління та аналізу великих даних, серед яких найбільш відомі і використовувані технології і засоби наступні:
− Big Table – запатентована розподілена система баз
даних, побудована на основі Google File System;
− Business Intelligence (бізнес-аналітика) –
сукупність методологій, процесів, архітектур і технологій, які перетворять
великі обсяги «сирих» даних в осмислену і корисну інформацію, придатну для
бізнес-аналізу і для підтримки прийняття оптимальних тактичних і стратегічних
рішень;
− Cassandra – вільно розповсюджувана система
управління базами даних, призначена для маніпулювання
даними величезного обсягу в розподілених системах;
− Cloud Computing (хмарні обчислення) –
обчислювальна парадигма, в якій високо масштабовані
обчислювальні ресурси, зазвичай сконфігуровані у вигляді
розподілених систем, надаються в мережах як сервісів;
− Data Warehouse (сховище даних) –
предметно-орієнтована інформаційна база даних, спеціально
розроблена і призначена для підготовки звітів і аналізу даних з метою
підтримки прийняття рішень в організації та є однією з основних
компонент бізнесаналізу. виступає центральним репозиторієм даних, що надходять
з різних джерел. зберігає поточні та історичні дані, будується на основі
систем управління базами даних і систем підтримки прийняття
рішень;
− Distributed System (розподілена система) – безліч
комп’ютерів, які взаємодіють по мережі та об’єднані для
вирішення загальної обчислювальної задачі;
− Dynamo – запатентована
розподілена система зберігання даних, розроблена в Amazon;
− Extract, Transform, And Load (витягти, перетворити, завантажити) – використовується для
отримання даних з зовнішніх джерел, перетворення їх для задоволення операційних
потреб, і завантаження їх в базу даних або сховище даних;
− Google File System – запатентована розподілена файлова система. на її основі
побудований Hadoop;
− Hadoop – проект фонду Apache Software Foundation, вільно розповсюджуваний набір утиліт, бібліотек іфреймворк для
розробки і виконання розподілених програм, що працюють на кластерах з сотень і
тисяч вузлів. використовується для реалізації пошукових і тематичних механізмів
багатьох високонавантажених веб-сайтів, в тому числі, для Facebook і Yahoo!. Базується на Mapreduce і Google File System;
− Hbase – вільно
розповсюджувана розподілена нереляційна база даних, яка створена на основі Big Table Google;
− Mapreduce – модель
розподілених обчислень, представлена компанією Google, яка використовується для
паралельних обчислень над дуже великими, аж до декількох петабайт, наборами даних в комп’ютерних
кластерах. Ця модель реалізована в Hadoop;
− Mashup – веб-додаток, що об’єднує дані з
декількох джерел в один інтегрований, наприклад, при
об’єднанні картографічних даних Google Maps з даними про нерухомість
з Craigslist виходить новий унікальний веб-сервіс, з самого
початку не пропонований жодним з джерел даних;
− R – вільно розповсюджувана мова програмування –
середовище програмування для статистичних і графічних обчислень;
− Stream Processing – технологія, призначена для
обробки великих потоків даних в реальному масштабі
часу.
3. Особливості
обробки багатомірних статистичних даних. Методи багатовимірної класифікації.
Обробка багатовимірних статистичних даних має певні особливості:
застосування методів багатомірного статистичного аналізу (БСА) вимагає творчого
підходу до розв’язання аналітичних задач, оскільки оброблюються багатовимірні
сукупності даних. Для
методів БСА характерна глибока формалізація та складна логіко-математична
конструкція, їх практичне застосування потребує використання обчислювальної
техніки.
Сучасні економічні умови потребують від суб’єктів господарювання
вміння аналізувати багатовимірні процеси та практично використовувати
результати аналізу даних для прийняття ефективних управлінських рішень.
В процесі вивчення різних, в тому числі економічних, об’єктів
важливу роль грає моделювання – метод дослідження, що полягає в побудові й
аналізі моделей-аналогів об’єктів дослідження.
Модель – образ реального об’єкта (процесу) в матеріальній або
ідеальній формі (тобто описаний знаковими засобами будь-якою мовою), що
відображає істотні властивості змодельованого об’єкта (процесу) й управління в
ході дослідження.
Моделювання – універсальний
спосіб вивчення процесів і явищ реального світу. Особливого значення воно
набуває у процесі вивчення об’єктів, не доступних прямому спостереженню та
дослідженню. До них, зокрема, відносять соціально-економічні явища та процеси.
Моделювання завжди має цільову спрямованість. Цілі та методи його можуть бути
різноманітними.
Економіко-математична
модель – це вираз формальної залежності у вигляді математичних
співвідношень (функцій, систем рівнянь або нерівностей, операторів тощо)
економічного процесу, проблеми або об’єкта, що досліджуються.
Економіко-математичне
моделювання методами багатовимірного аналізу – опис соціально-економічних систем знаковими
математичними засобами.
Розрізняють вербальне, геометричне
(предметне), фізичне й інформаційне моделювання:
- вербальне моделювання — моделювання на основі використання
розмовної мови;
- геометричне моделювання здійснюється на макетах або об’єктних
моделях. Ці моделі передають просторові форми об’єкта, пропорції тощо;
- фізичне моделювання застосовують для вивчення фізико-хімічних,
технологічних, біологічних, генних процесів, що відбуваються в оригіналі. Таке
моделювання називають аналоговим;
- інформаційне моделювання має фундаментальне значення в усіх галузях
науки (схеми, графіки, креслення, формули, рівняння, нерівності).
Найважливіша роль серед методів
інформаційного моделювання належить логіко-математичному моделюванню, тобто
моделюванню за допомогою застосування математичного апарату
багатовимірного статистичного аналізу.
Етапи дослідження за допомогою багатовимірного статистичного аналізу:
1. постановка задачі включає опис предметної
області об’єктів, визначення обсягів виділених ресурсів (час, трудовитрати і
т. д.);
2. визначення набору методів багатовимірного
статистичного аналізу та порядку їх використання;
3. збирання вихідних даних, визначення
способів збирання інформації, форм її подання;
4. аналіз даних (перевірка однорідності
вибірки, відповідність законам розподілу, виявлення грубих помилок і
т. д.);
5. уточнення математичної постановки задачі та
визначення можливості застосування раніше відібраних методів (у разі
необхідності набір методів змінюється);
6. реалізація — проведення обчислень,
реалізація за допомогою програмного забезпечення математичного інструментарію;
7. оцінювання адекватності моделі, визначення
несуперечності математичних результатів і економічних висновків.
В економічних дослідженнях кількість об’єктів
дослідження може досягати кількох десятків чи навіть сотень; а кількість ознак,
які їх характеризують, також може обчислюватися десятками. Очевидно, безпосередній
(візуальний) аналіз матриці даних за великої кількості об’єктів і ознак
практично малоефективний. Через це виникають завдання укрупнення, концентрації
вихідних даних, аналізу структури об’єктів дослідження. Вирішення цих завдань
може здійснюватися за допомогою сучасних методів багатовимірної класифікації.
Методи багатовимірної
класифікації дозволяють групувати об’єкти з
урахуванням усіх істотних структурно-типологічних ознак і характеру розподілу
об’єктів у заданій системі ознак. Така класифікація проводиться на основі
прагнення зібрати в одну групу в деякому сенсі схожі об’єкти, причому так, щоб
об’єкти з різних груп були за можливості несхожими.
Отже, методи багатовимірної класифікації
використовуються для розділення сукупності об’єктів на однорідні групи.
Водночас кожен об’єкт характеризується великим числом різних стохастично
пов’язаних ознак.
В економічних дослідженнях використовують
певні підходи до класифікації об’єктів і відповідні методи класифікації (рис.
4.1).
|
Підходи до класифікації об’єктів |
|
Методи класифікації об’єктів |
|
|
|
|
|
Розбиття або ієрархія класів |
|
Кластерний аналіз |
|
|
|
|
|
Віднесення елемента до системи класів |
|
Дискримінантний аналіз |
Рис. 4.1. Підходи до класифікації об’єктів
Кластерний аналіз застосовується у різноманітних економічних
дослідженнях. Наприклад, у маркетингу це сегментація конкурентів і споживачів. У менеджменті:
розбиття персоналу на різні за
рівнем мотивації групи, класифікація постачальників, виявлення схожих виробничих
ситуацій, за яких виникає брак. У фінансовому аналізі – для класифікації досліджуваних підприємств за
рівнем фінансового стану та ін. Також кластерний аналіз успішно застосовується для
проведення макроекономічних досліджень. Наприклад, для класифікації країн чи регіонів окремої країни
за рівнем життя населення, за станом трудових ресурсів, за рівнем туристичної
привабливості тощо.
Методи дискримінантного аналізу знаходять застосування практично
в усіх галузях: економіка, соціологія, медицина, психологія, управління.
Основна відмінність між методами кластерного і дискримінантного
аналізу полягає в тому, що в ході дискримінантного аналізу нові кластери не
утворюються, а формулюється правило, а яким нові одиниці сукупності відносять
до одного із уже існуючих класів. Дискримінантний аналіз дозволяє велику
неодноордну сукупність розбити на однорідні групи, а також віднести певний
об’єкт (явище, процес, спостереження) до конкретного класу.
4. Кластерний
аналіз.
Розглянемо
основі поняття кластерного аналізу.
Кластер (від англ. cluster) – група елементів, які характеризуються
будь-якою загальною властивістю.
Кластерний
аналіз – множина
обчислювальних процедур, що використовуються для класифікації (методи знаходження
кластерів).
Кластерний метод
– це багатовимірна статистична процедура, що виконує збірання даних, які
містять інформацію про вибір об’єктів, і потім упорядковує об’єкти в порівняно
однорідні групи.
Основні завдання
кластерного аналізу:
-
проведення класифікації об’єктів з урахуванням ознак, які
відображають сутність, природу об’єктів. Це приводить до поглиблення знань про
сукупність класифікованих об’єктів;
-
перевірка висунутих припущень про наявність певної структури в
дослідуваній сукупності об’єктів, тобто пошук існуючої структури;
-
побудова нових класифікацій для слабовивчених явищ, коли
необхідно встановити наявність зв’язків всередині сукупності та спробувати
привнести в неї структуру.
Об’єднання
схожих об’єктів у групи може бути здійснене різними способами, відповідно до
яких виділяють такі групи методів кластерного аналізу:
- ієрархічні;
- ітеративні;
- факторні;
- методи пошуку модальних значень щільності;
- методи, які використовують теорію графів.
Методи
кластерного аналізу відповідно до різних ознак класифікації подано в таблиці
4.1.
Таблиця 4.1
|
№ |
Ознака класифікації |
Методи кластерного аналізу |
|
1 |
За способом обробки даних |
- ієрархічні (агломеративні, дивізимні); - неієрархічні |
|
2 |
За способом аналізу даних |
- чіткі; - нечіткі |
|
3 |
За кількістю застосування
алгоритмів кластеризації |
- з одноетапною кластеризацією; - з багатоетапною кластеризацією |
|
4 |
За можливістю розширення обсягу
даних, які піддаються обробці |
- масштабовані; - немасштабовані |
|
5 |
За часом виконання
кластеризації |
- потокові (on-line) - непотокові (off-line) |
Найбільш поширеними
є ієрархічні методи кластерного аналізу, серед яких виділяють агломеративний і
дивізимний методи.
Агломеративного
метод полягає в тому, що на першому кроці кожен об’єкт вважається окремим
кластером. Два найбільш близьких об’єкта об’єднуються, і утворюється новий
кластер. Процедура триває, доки всі об’єкти не будуть об’єднані в один кластер.
Дивізимний метод
полягає в тому, що спочатку всі об’єкти належать одному кластеру. Від цього
кластера відокремлюються групи схожих між собою об’єктів. Так, на кожному кроці
кількість кластерів зростає, а міра відстані між класами зменшується.
Розглянемо критерії
якості кластеризації.
Заключним етапом процедури кластеризації є оцінювання якості
отриманої класифікації. Використання різних методів кластерного аналізу для тої
самої сукупності призводить до різних класифікацій об’єктів (різне число
кластерів, різна ступінь близькості об’єктів). Істотний вплив на характеристики кластерної
структури надають:
-
набір ознак кластеризації;
-
тип алгоритму кластеризації (метод
кластерного аналізу);
-
вибір міри подібності між об’єктами.
Виникає проблема вибору найбільш якісної
класифікації об’єктів, яка вирішується за допомогою критеріїв якості
класифікації об’єктів. Міру якості класифікації прийнято називати функціоналом,
або критерієм якості. Найкращим за обраним функціоналом вважають таку
класифікацію об’єктів, в якій досягається екстремальне (max / min) значення функціоналу якості.
Функціонал (критерій якості) класифікації –
певна міра якості, яка прагне до максимуму (мінімуму) залежно від змісту (рис.
4.2).
|
Сума квадратів відстаней до центрів класів |
|
|
|
|
|
|
|
Сума середньокласових відстаней між об’єктами |
|
|
|
|
|
|
|
Сумарна середньокласова дисперсія |
|
|

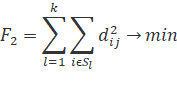

Рис. 4.2. Критерії якості класифікації
Позначення: l –
номер кластера (l=1, 2, … , k);
xl – центр l-го
кластера;
![]() – квадрат відстані між
між i-м об’єктом і центром
l-го кластера;
– квадрат відстані між
між i-м об’єктом і центром
l-го кластера;
![]() – квадрат
всередньокласових відстаней між обєктами;
– квадрат
всередньокласових відстаней між обєктами;
![]() – дисперсія j-ї змінної в кластері Sl.
– дисперсія j-ї змінної в кластері Sl.
Для оцінювання якості розбиття за мірою віддаленості
кластерів один від одного використовують середні міжкласові відстані. Для
перевірки гіпотези про рівність векторів середніх для багатовимірних
сукупностей використовується критерій Хоттелінга.
5.
Дискримінантний
аналіз.
Дискримінантний
аналіз є найважливішим інструментом під час вирішення задач класифікації. На
відміну від інших методів, дискримінантний аналіз дозволяє досліднику
спрогнозувати, до якого класу належить новий об’єкт. Він містить статистичні методи
класифікації багатовимірних об’єктів у ситуації, коли дослідник має так звані
навчальні вибірки (класифікація з навчанням).
Дискримінантний
аналіз – це розділ математичної статистики, змістом якого є розробка методу
розв’язання задач відмінності, тобто дискримінації об’єктів за певними
ознаками.
Завдання
дискримінантного аналізу:
- дозволяє інтерпретувати відмінності між існуючими класами
(визначає, які змінні дискримінують);
- дозволяє класифікувати нові об’єкти та віднести їх до одного з
класів.
Основні проблеми дискримінантного аналізу наведено
на рис. 4.3.
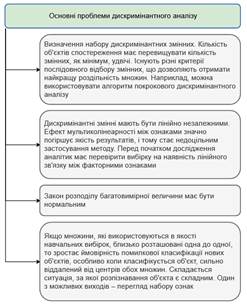
Рис. 4.3 – Основні проблеми дискримінантного аналізу
У вітчизняній
практиці використання методології багатофакторного дискримінантного аналізу має
ускладнення, що обумовлено, в першу чергу, такими факторами:
- відсутність вітчизняних розробок;
- відсутність необхідної бази даних;
- брак коштів для придбання іноземних методик та їх адаптації до
вітчизняних умов;
- необ’єктивна звітність підприємств;
- скептичне ставлення до можливих результатів.
Дискримінантні
змінні – це ознаки, які використовуються для того, щоб відрізняти один клас
(підмножину) від іншого.
Дискримінантна функція
– це гіперплощина, яка найкраще розділяє сукупність вибіркових точок.
Методи
дискримінантного аналізу:
- параметричні методи;
- непараметричні методи: лінійний дискримінантний аналіз Фішера,
канонічний дискримінантний аналіз, покроковий дискримінантний аналіз (із
включенням і виключенням).
![]()
![]()