6.1 Основні поняття
У попередніх розділах розглядався розв’язок
оптимізаційних задач, у яких вся вихідна інформація була однозначно визначена.
Така інформація називається детермінованою. Прикладом детермінованої вихідної
інформації можуть служити однозначні значення коефіцієнтів сi, aij і
bj (i=1,2,...n; j=1,2,...m) у лінійній математичній моделі (2.1). У
практичних задачах далеко не завжди вихідна інформація буває детермінованою.
Досить часто вихідна інформація або її частина являють
собою випадкові величини або випадкові функції. Наприклад, потужності
навантажень у проектованій системі електропостачання можна вважати випадковими
величинами, а зміни в часі напруг у вузлах існуючої системи електропостачання ‑
випадковими функціями. Для розв’язку оптимізаційних задач із випадковою
вихідною інформацією використовуються методи стохастичного програмування.
Відомо, що випадковими величинами займається розділ вищої
математики ‑ теорія ймовірностей.
Тому перш ніж перейти до методів розв’язку оптимізаційних задач згадаємо деякі
поняття цієї теорії.
Випадковою
величиною s називається така величина, що може
прийняти те або інше значення, причому заздалегідь невідомо, яке саме.
Випадкова величина s
може бути безперервною або дискретною. У заданому діапазоні зміни
випадкової величини кількість значень дискретної випадкової величини є
обмеженим, а кількість значень безперервної випадкової величини є необмеженим.
Прикладом безперервної випадкової величини є величина напруги в деякому вузлі
системи електропостачання. Прикладом дискретної випадкової величини є кількість
генераторів, які одночасно працюють в енергосистемі.
Математичним
сподіванням випадкової величини називається її
середнє значення, яке отримане в результаті n
реалізацій:
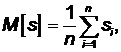 (6.1)
(6.1)
де si ‑ значення
випадкової величини в i-й реалізації.
Середньоквадратичне
(стандартне) відхилення визначає розкид
значень випадкової величини відносно її математичного сподівання:
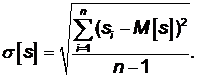 (6.2)
(6.2)
Важливою характеристикою випадкової величини служить ймовірність Р появи цієї випадкової
величини в конкретному інтервалі значень.
Для кількісної оцінки ймовірності випадкової величини
вводиться функція розподілу ймовірності.
Припустимо, що випадкова величина s
може приймати значення від ![]() до
до ![]() . Функція розподілу Р(s)
цієї випадкової величини показує імовірність того, що випадкова величина
потрапить в інтервал від
. Функція розподілу Р(s)
цієї випадкової величини показує імовірність того, що випадкова величина
потрапить в інтервал від ![]() до s. Отже,
до s. Отже,
![]() (6.3)
(6.3)
Найбільше поширення на практиці одержав нормальний закон
розподілу. Відповідно до цього закону з імовірністю 0,999 випадкова величина![]() перебуває в інтервалі:
перебуває в інтервалі:
![]() (6.4)
(6.4)
що й приймається за дійсні межі зміни випадкової величини s.
При розв’язуванні практичних задач досить часто
застосовують нормальний стандартний закон
розподілу. Цей закон описує ймовірність появи стандартної випадкової
величини ![]() , що має математичне сподівання
, що має математичне сподівання ![]() і середньоквадратичне
відхилення
і середньоквадратичне
відхилення ![]() , в інтервалі
, в інтервалі ![]() (рис. 6.1).
(рис. 6.1).
За допомогою цього графіка вирішуються дві протилежні
одна одній задачі. З одного боку, визначається, яке повинне бути значення
випадкової величини ![]() , щоб імовірність її появи склала, наприклад
, щоб імовірність її появи склала, наприклад ![]() . Це значення випадкової величини становить
. Це значення випадкової величини становить ![]() . З іншого боку, визначається ймовірність появи випадкової
величини
. З іншого боку, визначається ймовірність появи випадкової
величини ![]() , яка не перевищує, наприклад, значення 0,84 (
, яка не перевищує, наприклад, значення 0,84 (![]() ). Ця ймовірність становить
). Ця ймовірність становить![]() .
.
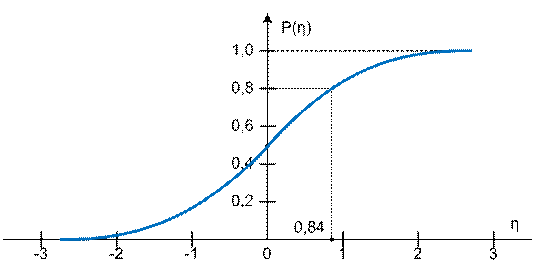
Рис. 6.1. Функція розподілу нормального
стандартного закону
В MS Excel ці два обчислення
виконуються за допомогою статистичних функцій НОРМСТОБР(0,8)=0,84 і
НОРМСТРАСП(0,84)=0,8 після звертання до майстра функцій ![]() в головному меню.
в головному меню.
Від функції розподілу нормального стандартного закону можна
перейти до функції розподілу нормального закону будь-якої випадкової величини s оптимізаційної задачі. Зв'язок між
цією випадковою величиною s і
стандартною випадковою величиною ![]() виражається
залежністю:
виражається
залежністю:
![]() (6.5)
(6.5)

