Тема 9
Інтеграція великих даних та ІоТ-технологій
Системи
великих даних (Big Data) відіграють ключову роль у сучасних технологіях,
особливо коли йдеться про Інтернет речей (IoT). IoT генерує величезні обсяги
даних з мільярдів підключених пристроїв — від розумних термостатів до
промислових сенсорів. Щоб ефективно зберігати, обробляти та аналізувати ці
дані, використовуються спеціалізовані платформи та інструменти, що входять до
складу екосистеми великих даних.
Основи систем великих даних для IoT
Основною
метою систем великих даних у контексті IoT є збирання, зберігання та обробка
даних, що генеруються підключеними пристроями. Ці дані можуть бути
структурованими (наприклад, записи в базах даних) або неструктурованими
(наприклад, відео, аудіо або тексти). Системи великих даних повинні бути здатні
обробляти ці дані в режимі реального часу або з мінімальними затримками, що є
критичним для забезпечення ефективної роботи IoT-рішень, таких як розумні
міста, автономні автомобілі або промислова автоматизація (рис. 10).

Рисунок 10 – Основи систем великих даних для IoT
Стек та інструменти платформи великих даних
Стек
технологій великих даних складається з кількох рівнів, кожен з яких виконує
певні функції в обробці та управлінні даними. На нижньому рівні знаходяться
інструменти для збору та зберігання даних. Серед найбільш відомих платформ
можна виділити Apache Hadoop і Apache Spark, які забезпечують розподілене
зберігання та обробку даних на кластерах серверів. Ці платформи здатні
обробляти петабайти даних, що дозволяє їм підтримувати навіть найбільші
IoT-екосистеми (рис. 11).
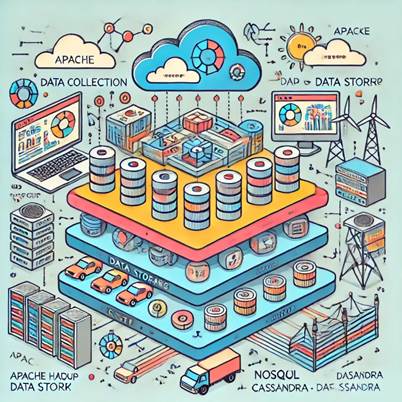
Рисунок 11 – Різні рівні стека, включаючи збір даних,
зберігання, обробку та аналітику, з зазначенням відповідних інструментів для
кожного рівня
На
наступному рівні знаходяться інструменти для обробки даних. Apache Kafka
використовується для потокової обробки даних в реальному часі, дозволяючи
передавати дані від IoT-пристроїв до хмарної інфраструктури для подальшої
аналітики. Apache Flink і Apache Storm є іншими важливими інструментами для
обробки даних у потоках, які використовуються для складних аналітичних задач.
Для
зберігання великих обсягів даних також використовуються NoSQL бази даних, такі
як Apache Cassandra або MongoDB, які забезпечують високу доступність та
масштабованість, необхідні для IoT-застосунків. Ці бази даних можуть ефективно
обробляти великий потік даних, що надходить від різноманітних джерел.
На
верхньому рівні знаходяться інструменти для аналітики та візуалізації даних.
Наприклад, Apache Zeppelin або Kibana використовуються для створення звітів і
дашбордів, що дозволяють візуалізувати результати обробки даних і надавати їх у
зручному форматі для прийняття управлінських рішень.
Архітектури систем великих даних
Архітектура
систем великих даних (рис. 12) часто будується на принципах розподіленого
зберігання і обробки даних, що дозволяє ефективно масштабувати рішення у
відповідь на зростання обсягів даних. Типова архітектура включає кілька шарів,
кожен з яких виконує специфічну функцію.
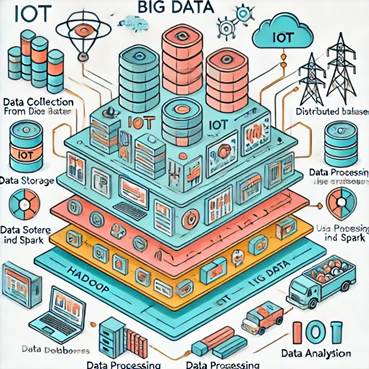
Рисунок 12 – Архітектура системи великих даних, які
використовуються в IoT
На
початковому етапі дані збираються з різних джерел — сенсорів, мобільних
пристроїв, соціальних мереж або логів серверів. Дані потрапляють у систему
через так званий «шар збору даних», де вони можуть бути попередньо оброблені
для видалення шуму або дублювання.
Наступний
шар — це «шар зберігання», де дані зберігаються в розподілених файлових
системах або базах даних. Цей шар забезпечує надійність і доступність даних для
подальшої обробки.
«Шар
обробки» відповідає за трансформацію та аналіз даних. На цьому рівні
використовуються різні алгоритми машинного навчання або аналітичні інструменти,
щоб виявити приховані закономірності або тренди.
Останній
шар — це «шар представлення», де результати аналізу даних виводяться у
зрозумілому форматі через дашборди, звіти або інтерактивні візуалізації.
Вимоги до систем великих даних
Системи
великих даних повинні відповідати низці вимог для забезпечення ефективної
роботи в умовах високих навантажень і постійного зростання обсягів даних.
По-перше, вони мають бути масштабованими, тобто здатними обробляти все більше
даних без втрати продуктивності. Це означає, що системи повинні легко
адаптуватися до додавання нових серверів або збільшення обчислювальної
потужності.
По-друге,
системи великих даних повинні забезпечувати високу надійність та
відмовостійкість. Це досягається шляхом дублювання даних та використання
алгоритмів, що дозволяють продовжувати обробку навіть у випадку виходу з ладу
частини інфраструктури.
По-третє,
вони повинні забезпечувати низькі затримки при обробці даних, особливо у
випадку з IoT, де реальний час є критичним. Це важливо для додатків, які
потребують миттєвих відповідей, наприклад, у системах автономного керування
транспортом або у промислових процесах.
Нарешті,
системи великих даних повинні бути безпечними, оскільки вони обробляють велику
кількість конфіденційної інформації. Це включає в себе захист даних на всіх
етапах – від зберігання до передачі і обробки, а також управління доступом до
цих даних.
Ці
вимоги роблять системи великих даних складними, але водночас потужними
інструментами для роботи з IoT, дозволяючи компаніям максимально ефективно
використовувати всі переваги, які пропонують сучасні технології.

