Тема 6
Великі дані для систем на основі IoT
Великі дані — це концепція, що стосується
збору, зберігання та аналізу величезних обсягів даних, які неможливо ефективно
обробити за допомогою традиційних систем управління базами даних (СУБД). Великі
дані характеризуються трьома основними: обсягом (Volume), швидкістю (Velocity)
та різноманітністю (Variety). Обсяг відображає кількість даних, швидкість —
швидкість їх створення та обробки, а різноманітність — типи даних
(структуровані, напівструктуровані, неструктуровані).
Для
обробки великих даних використовуються спеціалізовані технології, серед яких
бази даних NoSQL займають важливе місце. Бази даних NoSQL пропонують гнучкіші
моделі зберігання даних порівняно з традиційними реляційними базами даних, що
дозволяє обробляти великі обсяги даних із високою швидкістю.
Бази даних NoSQL.
NoSQL
бази даних мають різні моделі даних: документи, графи, ключ-значення, колонки.
Вони не використовують SQL як основну мову запитів, хоча багато з них можуть
мати схожі на SQL інтерфейси. NoSQL бази даних забезпечують горизонтальне
масштабування, що дозволяє розподіляти дані між кількома серверами для
забезпечення високої доступності та швидкої обробки.
Apache Cassandra.
Apache
Cassandra (рис. 1) є одним із найпопулярніших рішень серед NoSQL баз даних.
Вона була створена для забезпечення стійкості до відмов і масштабованості в
розподілених системах. Cassandra є децентралізованою системою без єдиної точки
відмови, що робить її особливо корисною для обробки великих даних у різних
географічно розподілених середовищах.
Рисунок 1 – Архітектура Apache Cassandra
Архітектурні
особливості Cassandra:
·
Розподілена
архітектура: Усі вузли в кластері є рівноправними, що
означає відсутність головного вузла або центрального координатора. Це
забезпечує стійкість до відмов і можливість додавання нових вузлів без зупинки
системи.
·
Використання
комутатора: Для забезпечення відмовостійкості Cassandra
використовує метод реплікації даних між кількома вузлами. Це означає, що одна і
та ж інформація зберігається на кількох серверах, що дозволяє забезпечити
доступ до даних навіть у випадку виходу з ладу одного або декількох вузлів.
·
Транзакції
та консистентність: Cassandra не підтримує традиційні
ACID-транзакції. Натомість вона забезпечує принцип BASE (Basic Availability,
Soft state, Eventual consistency), що дозволяє досягти високої продуктивності
за рахунок можливості тимчасових невідповідностей у даних.
Моделювання даних у Cassandra.
Моделювання
даних у Cassandra (рис. 2) відрізняється від традиційних реляційних баз даних.
Основний підхід полягає в тому, що структура таблиць розробляється на основі
запитів, які повинні бути ефективно оброблені системою. Це означає, що
необхідно заздалегідь передбачити, які типи запитів будуть виконуватися до
даних, і відповідно до цього спроєктувати таблиці.
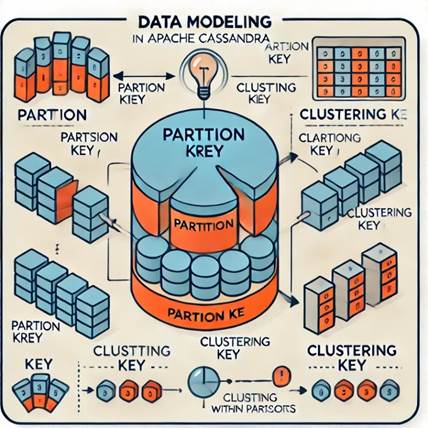
Рисунок 2 – процес моделювання даних у Apache Cassandra
Ключові елементи
моделювання:
·
Ключі
розподілу (Partition Keys): Це ключові атрибути, які
використовуються для визначення, на якому вузлі буде зберігатися даний запис.
Вибір ключів розподілу є критично важливим для забезпечення рівномірного
розподілу даних і запобігання надмірному навантаженню на окремі вузли.
·
Денормалізація:
У Cassandra часто використовується практика денормалізації даних. Це означає,
що одна і та ж інформація може зберігатися в різних таблицях для забезпечення
швидкого доступу до неї. Це суперечить традиційним принципам нормалізації в
реляційних базах даних, але значно підвищує продуктивність у розподілених
системах.
·
Кластерні
ключі (Clustering Keys): Вони визначають порядок
сортування даних у межах розділу (partition). Це дозволяє ефективно виконувати
діапазонні запити в межах одного розділу.
Методологія оптимального налаштування узгодженості в
Cassandra.
У
Cassandra узгодженість даних (рис. 3) визначається тим, як швидко дані,
записані в систему, стають доступними для читання іншими вузлами. Cassandra
пропонує гнучке налаштування рівня узгодженості, що дозволяє знаходити баланс
між швидкістю запису/читання і точністю даних.
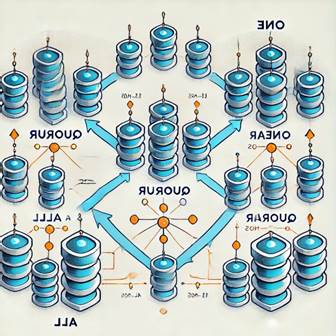
Рисунок 3 – Рівні узгодженості в
Apache Cassandra
Типи узгодженості:
· ONE: Запит вважається успішним,
якщо запис або читання було підтверджено хоча б одним вузлом.
· QUORUM: Вимагає, щоб більшість вузлів
підтвердили операцію. Це дозволяє досягти балансу між узгодженістю та
доступністю.
· ALL: Запит вважається успішним
тільки тоді, коли всі вузли підтвердили операцію. Це забезпечує найвищий рівень
узгодженості, але знижує доступність.
· LOCAL_QUORUM: Операція повинна бути
підтверджена більшістю вузлів у локальному центрі обробки даних, що дозволяє
зберегти баланс між узгодженістю і продуктивністю в межах одного регіону.
Оптимальне налаштування узгодженості.
Для
досягнення оптимального балансу між доступністю, узгодженістю та швидкістю
обробки даних, налаштування узгодженості повинно відповідати специфічним
вимогам вашої системи. Наприклад, у випадках, коли важлива швидкість обробки,
можна використовувати менш строгі рівні узгодженості (наприклад, ONE або
LOCAL_QUORUM). Однак, якщо точність даних є критично важливою, слід обирати
більш строгі рівні, такі як QUORUM або ALL.
Крім
того, важливо проводити постійний моніторинг та тестування системи для
визначення оптимальних параметрів, з урахуванням зміни навантажень та характеру
даних.
Таким
чином, Cassandra дозволяє створювати ефективні та масштабовані системи для
обробки великих даних, забезпечуючи високу продуктивність і можливість
налаштування рівня узгодженості для досягнення необхідного балансу між
доступністю та точністю даних.

