Лекція 8. Моніторинг та визначення несправностей комп’ютерної системи
1. Моніторинг комп’ютерної системи
Щоб працювати не тільки за фактами інцидентів, а попереджати можливі відмови системний адміністратор істотну частину свого робочого часу повинен витрачати на оцінку стану обладнання та програмних забезпечення, переглядання протоколів роботи різних служб і т. д.
Аналіз одержаної інформації зазвичай потребує високої кваліфікації, будучи при цьому вельми рутинною операцією. Навіть якщо адміністратор і не нехтує цією частиною своїх повсякденних обов'язків, тим не менше, всі ці зусилля не можуть гарантувати контроль функціонування компонентів в реальному часі.
Тому наявність тієї чи іншої системи моніторингу системи є вимогою до сучасної інформаційної системи.
Основні способи контролю комп’ютерної системи
Для моніторингу системи традиційно використовують:
- аналіз повідомлень в журналах системи;
- SNMP-протокол (для контролю активного обладнання);
- імітація запитів до системи (наприклад, тестовий запит до бази даних);
- спеціальні агенти, які додатково встановлені в систему (для розширеного моніторингу).
Nagios
Nagios є програмою моніторингу інформаційних систем на основі відкритого коду (рис. 7.1). Продукт є практично стандартом для систем моніторингу.
Вона дозволяє:
- контролювати хости (завантаження процесора, використання диска, журнали і т. д.) з різноманітними операційними системами – Windows, Linux, AIX, Solaris і т. д.;
- контролювати мережеві служби (SMTP, POP3, HTTP, SSH і т. д.);
- підключати додаткові модулі розширення (плагіни) написані різними мовами програмування (Shell, C++, Perl, Python, PHP, C# та ін. – архітектура модулів повинна бути відкрита), використовувати власні способи перевірки служб;
- здійснювати паралельних перевірку систем (для підвищення продуктивності);
- відправляти оповіщення у разі виникнення проблем за допомогою електронної пошти, повідомлень SMS і т. д.;
- автоматично реагувати на події служби або хоста.
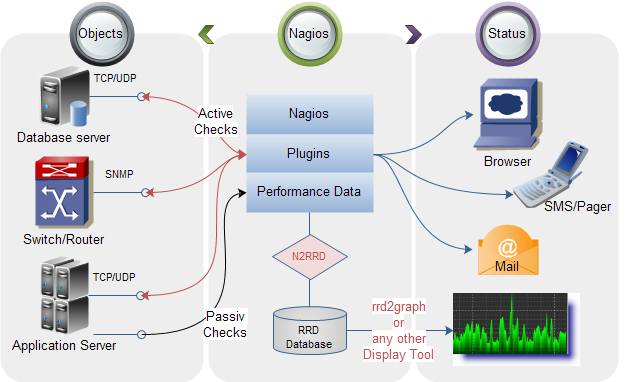
Рис. 7.1 – представлення інтерфейсу Nagios
ZABBIX
ZABBIX – вільна система моніторингу та відстеження статусів різноманітних сервісів комп'ютерної мережі, серверів та мережевого обладнання, написана Олексієм Владишевим (Литва). Для зберігання даних використовується MySQL, PostgreSQL, SQLite або Oracle (рис. 7.2).
Веб-інтерфейс написаний на PHP. ZABBIX підтримує кілька видів моніторингу:
Simple checks – може перевіряти доступність і реакцію стандартних сервісів, таких як SMTP або HTTP без установки будь-якого програмного забезпечення на хості за яким спостерігають.
ZABBIX agent – може бути встановлений на UNIX-подібних або Windows хостах для отримання даних про навантаження процесора, використання мережі, дискового простору і т. д.
External check – виконання зовнішніх програм. ZABBIX також підтримує моніторинг через SNMP.
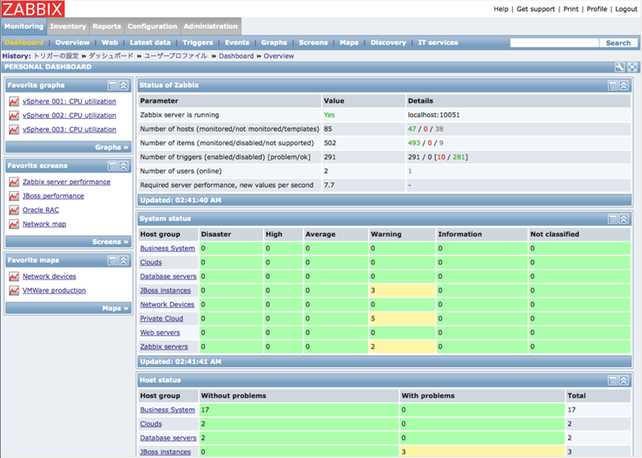
Рис. 7.2 – представлення інтерфейсу Zabbix
Ganglia
Ganglia – масштабована розприділена система моніторингу кластерів паралельних і розподілених обчислень та хмарних систем з ієрархічною структурою (рис. 7.3). Дозволяє відстежувати статистику та історію (завантаженість процесорів, мережі) обчислень в реальному часі для кожного з спостережуваних вузлів.
Проект створений в 1998 році в Каліфорнійському університеті в Берклі як продовження проекту Millennium, який був ініційований Національним науковим фондом США.
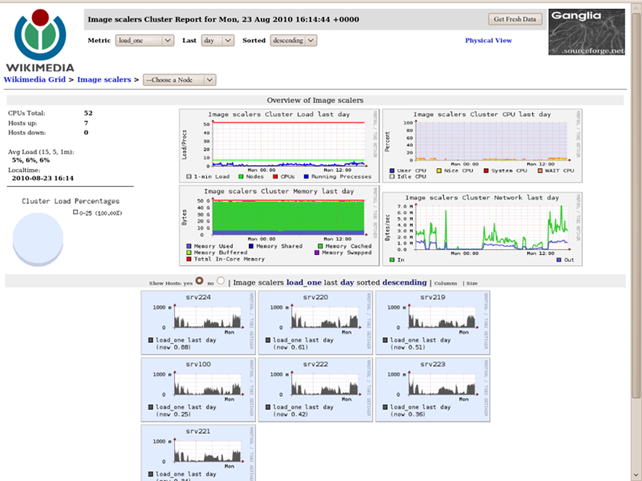
Рис. 7.3 – представлення інтерфейсу Ganglia
2. Визначення несправностей та порядок налаштування комп’ютерної системи
Відмови інформаційної системи все більшою мірою впливають на ефективність бізнес-процесів підприємства, тому одне з головних завдань адміністратора працюючої системи полягає в попередженні відмов і максимальному скороченні часу простою обслуговування.
Перш ніж почати ...
Якщо відмова все ж сталася, не поспішайте відразу ж починати щось робити.
Спробуйте заспокоїтися, можна випити кави і тільки після цього приступати до активної діяльності.
Насамперед, спробуйте отримати про несправність максимум інформації як від користувачів, так і за даними об'єктивного контролю.
Спробуйте конкретизувати проблему. Після цього слід скласти попередній перелік можливих причин відмови з оцінкою часу усунення по кожній позиції. Намагайтеся не починати ремонт з найбільш витратних позицій, якщо тільки ви абсолютно не впевнені, що саме вони стали причиною несправності.
Виконайте операції, які ви запланували для ліквідації відмови. Перевірте результат. Якщо Ви не досягли успіху, то доведеться повторити кроки: висловити нові припущення про причини, скласти новий план дій і т. д.
Не намагайтеся вносити відразу багато змін в налаштування. Протоколюється всі свої кроки. Часто, якщо систему не вдається відновити за короткий час, без таких записів дуже складно не заплутатися і повернутися до вихідної точки.
Якщо ви довго не можете впоратися з відмовою, спробуйте розповісти про несправності кому-небудь ще. По-перше, намагаючись пояснити проблему, ви розкладете її для себе «по поличках». По-друге, поради неспеціалістів часто можуть направити вас на несподіваний шлях вирішення.
Обов'язково складіть який-небудь документ за результатами інциденту, щоб фахівцю, який прийде на ваше місце, було легше орієнтуватися в стані системи.
П'ять дев'яток?
Мета, яку ставлять виробники устаткування і розробники програмного забезпечення, – досягти доступності інформаційної системи на «п'ять дев'яток» – 99,999%. При цілодобовій роботі цей показник відповідає приблизно п'яти хвилинам простою за рік.
Звичайно, досягнення такого показника вимагає дуже істотних витрат як на відповідне обладнання, так і на обслуговування, нереальних для малих і середніх організацій. У той же час в силах системного адміністратора як налагодити роботу з попередження відмов, так і створити умови для оперативного відновлення інформації. Адміністратор повинен бути готовий до виникнення будь-якої нештатної ситуації і мати певний план дій – план забезпечення неперервності функціонування інформаційної системи.
Подібний план являє собою перелік заходів, які необхідно здійснити в разі відмови обладнання або в іншій нештатній ситуації. У ньому має бути визначено, наприклад, на яке обладнання перенести сервери в разі його відмови? Де повинні зберігатися дистрибутиви, щоб відновлення могло бути проведено черговим оператором? Яка повинна бути процедура відновлення даних? Описавши всі передбачувані аварійні ситуації та шляхи їх усунення, ви зможете розрахувати очікуваний час відновлення системи у кожному випадку відмови.
Саме при складанні плану забезпечення безперервної роботи можна оцінити вартість відновлення системи при різних відмовах і для деяких випадків спочатку відмовитися від можливості оперативного відновлення. Досить співвіднести витрати на підтримку відмовостійкості з потенційними втратами від відмови в обслуговуванні і прийняти зважене рішення.
Якщо такий план буде затверджений керівництвом, то, з одного боку, ви отримаєте захист від невиправданих вимог негайного відновлення роботи, оскільки для кожної ситуації досяжні тимчасові рамки будуть чітко обумовлені. З іншого боку, цей план стане інструкцією, що потрібно робити в аварійній ситуації.
Будьте готові до гіршого
Продумуючи заходи щодо забезпечення безперервної роботи інформаційної системи, слід враховувати всі можливості: в реальному житті відбуваються найнесподіваніші відмови і необхідно зустрічати їх підготовленими.
Будьте готові, що незалежно від прийнятих заходів захисту ваша система або може бути зламана, або виникне інша ситуація з повною втратою даних.
І практично єдине, що може допомогти, – це підготовленість до відновлення даних «з нуля», наявність і регулярне створення резервних копій інформації.
Отримати копію даних, достатню для повного відновлення сервера, можна різними способами. Починаючи від звичайних операцій копіювання на змінний носій і закінчуючи комерційними системами підтримки актуальної копії даних в реальному режимі часу. Все залежить від вимог, що пред'являються до інформаційної системи. Скільки даних може бути втрачено, за який період часу система повинна бути відновлена «з нуля» і т. д.
Головне, що потрібно запам'ятати, – резервна копія, резервна копія і ще раз резервна копія!
Запасні деталі
Будь-яка інформаційна система потребує ЗІП – запасних інструментів і приладів. В ідеалі склад ЗІП повинен розраховуватися при створенні системи, але зазвичай для цього не вистачає показників надійності і ЗІП складається у відсотках від обсягу (наприклад, 10% – цифра залежить від практики, прийнятої на конкретному підприємстві), але не менше одного елемента кожного типу.
Слід врахувати, що запасні деталі до обладнання, що знаходиться на експлуатації більше 3-х років, придбати стає вельми складно. Часто для цього необхідна наявність сервісних контрактів, вартість яких за 3-5 років вже починає перевищувати вартість вихідного обладнання.
Тому при придбанні обладнання потрібно одночасно купувати запасні жорсткі диски, блоки живлення, сполучні кабелі і т. д. Не кажучи вже про те, що у системного адміністратора повинен бути запас таких компонентів, що найчастіше виходять із ладу, як клавіатури, миші, пасивне обладнання.
Збір інформації про відмову
Для успіху відновлення велике значення має якість зібраної інформації про відмову. Спочатку перевірте здається очевидні факти: чи включено обладнання, чи горять індикатори стану, чи не з'явилися додаткові шуми і т. д.
Потім систематизуйте інформацію про систему:
- публічні журнали (журнал подій Windows, syslog для unix-систем, журнали додатків);
- уточніть час виникнення проблеми, які операції виконувалися в цей момент;
- з'ясуйте, чи проводилися зміни в налаштуваннях системи перед виникненням проблеми, чи змінювалося обладнання і т. д.;
- проаналізуйте ситуацію: чи зустрічалися спостережувані симптоми раніше, чи були подібні відмови, які могли призвести до поточної проблеми і т.д.;
- якщо помилка спостерігається у користувача, переговоріть з ним, уточніть ситуацію, спробуйте відтворити проблему.
Контрольні запитання:
1. Назвіть завдання моніторингу комп’ютерної системи.
2. Які Ви знаєте способи моніторингу та контролю комп’ютерної системи.
3. Програмні засоби моніторингу інформаційних систем.
4. Які основні кроки потрібно здійснити для виявлення несправностей комп’ютерної системи.
5. Порядок налаштування комп’ютерної системи.