Тема. Методи тестування
План
1. Методи тестування, їх класифікація і умови застосування.
2. Стратегії тестування, базовані на коді.
3.
Критерії покриття рядків, розгалужень, покриття умов.
4.
Тестування циклів. Тестування потоків даних.
1. Методи тестування, їх класифікація і умови застосування
Якщо визначати тестування в
його розширеному змісті як будь-яку перевірку програми, то методи тестування можна
розділити на дві великі категорії:
1. Методи статичного тестування:
без виконання програми (перевірка текстів, трасування текстів, інспекції).
Інструменти тестування — аналізатори коду.
2. Методи динамічного тестування:
виконання програми і аналіз результатів.
Методи
динамічного тестування
Методи тестування
розрізняються підходами до проектування тестів.
Традиційно методи
динамічного тестування розділяють на дві категорії — «чорний ящик» (без доступу
до початкового коду – “black box”) і «білий ящик» (з доступом до початкового
коду – “white box”). Докладніша класифікація методів тестування, базована
на підходах до проектування тестів, зображена на мал. 7.
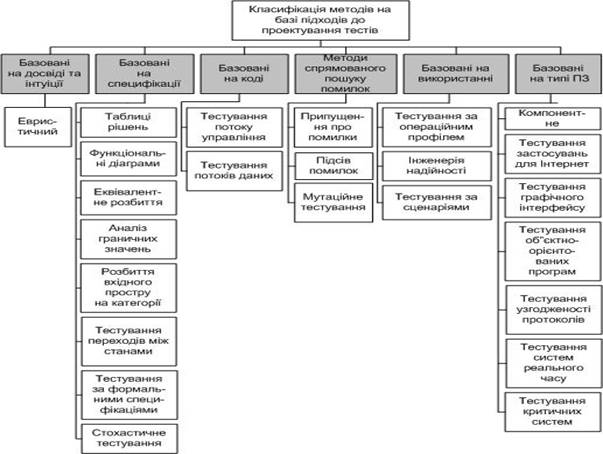
Мал.
7. Класифікація методів тестування
1.
Методи тестування, базовані на
досвіді та інтуїції.
Спеціалізоване тестування (Ad hoc). Це
найбільш поширений (хоча і не систематичний) підхід, при якому тести
розробляються виходячи з інтуїції тестера і його досвіду в тестуванні подібних
систем. Ефективність підходу повністю визначається майстерністю виконавця.
Підхід не вимагає докладної специфікації функцій ПЗ, але і не забезпечує
оцінювання повноти тестового покриття. Розвитком підходу можна вважати
«дослідницьке тестування» (exploratory testing), основні принципи якого –
поєднання вивчення програмного продукту з проектуванням тестів і їх виконанням.
Таке тестування звичайно
здійснюється незалежними тестерами стосовно завершених програмних
продуктів.
2.
Методи, базовані на специфікації (або методи функціонального
тестування).
У традиційній класифікації їх
відносять до методів «чорного ящика». Вони застосовуються для тестування
зовнішніх і внутрішніх функцій програми і припускають наявність специфікації
(формальної або неформальної), використовуваної як еталон. Методи відрізняються
між собою підходами до вибору тестових даних з множини входів (вхідного
простору) функцій.
До основних методів
функціонального тестування відносять:
ü таблиці рішень;
ü функціональні діаграми;
ü еквівалентне розбиття;
ü аналіз граничних значень;
ü розбиття вхідного простору на категорії;
ü тестування переходів між станами;
ü тестування на основі формальних специфікацій.
Метод, що використовує таблиці
рішень для проектування тестів, був запропонований Дж. Гуденафом і С. Герхартом.
Кожна колонка такої таблиці представляє комбінацію умов, які можуть істотно
вплинути на виконання програми. Ці умови ідентифікуються на основі аналізу
специфікацій. Потім визначається множина їх можливих значень і встановлюються обмеження щодо їх сумісності.
Таким чином, скорочується кількість тестових предикатів (наприклад, обмеження
може говорити про те, що, якщо умова 1 виконується, то ні умова 2, ні умова 3
не можуть виконуватися).
Другий метод, запропонований
Б. Ельмендорфом і описаний Г. Майерсом, полягає в перетворенні специфікації
у функціональні діаграми. За цим методом спочатку
ідентифікується кожна окрема функція, потім визначаються всі причини, що
впливають на її поведінку, і всі відповідні наслідки (реакції). Наступний крок
полягає в побудові діаграми, що зв’язує комбінації причин з очікуваними
реакціями на них. Далі для кожного наслідку, зазначеному на діаграмі,
визначаються тестові набори шляхом перебору всіх комбінацій причин, що
породжують цей наслідок.
Хоча чітке дотримання методу
може забезпечити побудову ефективних тестів, він складний у практичному
застосуванні для функціонально складних програм, оскільки із зростанням числа
причин ускладнюється граф причинно—наслідкових зв’язків, а встановлення
обмежень пов’язане з додаванням нових проміжних вузлів.
У
методі еквівалентного
розбиття множина значень вхідних даних функції, які
утворюють її вхідний простір, розбивається на набір підмножин таким чином, що в
кожну підмножину потрапляють значення, еквівалентні одне одному з погляду їх
використовування в тестах для виявлення помилок. Говорять, що всі тести, які можуть бути побудовані на
основі еквівалентних значень, представляють один «клас еквівалентності», і для
тестування достатньо вибрати тільки найефективніші з них.
У
методі аналізу
граничних значень, що доповнює попередній метод,
дані вибираються на межах вхідної області, оскільки багато які відмови
відбуваються через дефекти, пов’язані з обробкою граничних значень входів.
Методи
еквівалентного розбиття і аналізу граничних значень вважаються базовими методами функціонального
тестування і повинні застосовуватися спільно під час проектування набору тестів
для кожного рівня тестування.
У розвиток цих методів був
створений метод, який базується на специфікаціях функцій, і використовує для
побудови функціональних тестів розбиття вхідного простору функцій на певні категорії.
Суть методу полягає у ряді послідовних декомпозицій функції, починаючи з
початкової функціональної специфікації і кінчаючи
окремими деталями кожної процедури, що тестується, і в створенні специфікацій
тестів на основі виділення категорій інформації про параметри функції і умов її
виконання.
У
методі тестування переходів між станами програма
представляється у вигляді моделі, що відображає всі можливі стани її виконання,
переходи між цими станами, події, які викликають переходи, і подальші дії з
обробки даних, що визначаються цими переходами.
Опис специфікацій на
формальній мові дозволяє автоматично будувати по них функціональні тести і в
той же час забезпечує еталон для перевірки результатів. Існує цілий ряд методів генерації тестів
за формальними специфікаціями.
При випадковому тестуванні
вхідні дані для тестів вибираються випадково. Як інструмент генерації вхідних
даних можуть застосовуватися випадкові числа. Для інтерактивних програм тестер
використовує випадкову комбінацію дій з програмою, намагаючись виявити області
її нестійкого функціонування.
3. Методи, засновані на аналізі
коду (або структурні).
У традиційній класифікації
структурні методи відносять до методів «білого ящика». За цими методами
структура програми представляється у вигляді направленого графу, в якому ідентифікуються
потоки управління або потоки даних. Відповідно, методи діляться на дві основні
категорії: тестування потоку управління (шляхів) і
тестування потоку даних.
Це основні методи, які
використовуються на модульному рівні.
4.
Методи цілеспрямованого пошуку помилок.
Ці методи використовуються
для проектування тестів, спеціально призначених для виявлення помилок певних
типів.
До основних методів цієї
категорії відносяться:
ü припущення про помилки (error guessing);
ü підсів помилок (error seeding);
ü мутаційне тестування (mutation testing).
За методом припущень
про помилки на підставі «історичної» інформації про помилки,
знайдені в подібних програмах, досвіду тестерів, а також каталогів відомих
помилок, складається список можливих помилок і помилкових ситуацій. Одним з
«класичних» прикладів застосування методу є перевірка операції ділення на 0. У традиційній класифікації
метод відноситься до категорії методів «чорного ящика».
Методи підсіву помилок і
мутаційного тестування призначені для перевірки ретельності вже
виконаного тестування. У традиційній класифікації вони відносяться до категорії
методів «білого ящика».
В методі підсіву
помилок – у код, протестований на певному наборі тестів,
спеціально вноситься невелика кількість помилок, а потім програма повторно
тестується. Якщо під час тестування виявляються не всі внесені помилки, набір тестів
вважається не достатнім. Відношення кількості знайдених внесених помилок до
загальної кількості внесених помилок вважається приблизно рівним відношенню
кількості знайдених реальних помилок до загальної кількості помилок, що
містяться в програмі. Якщо виявлені всі внесені помилки, то вважається, що або
набір тестів достатній, або, що ці помилки було дуже легко знайти.
Під час
мутаційного
тестування створюється багато копій основної програми, в кожну
з яких вноситься невелика зміна, названа «мутацією», для імітації помилки в
операторі або операнді, що не відображається на синтаксичній коректності
програми. Кожна
копія тестується на одному і тому ж наборі тестів. Якщо в процесі тестування
всі внесені зміни знайдені, програма вважається протестованою адекватно і
коректною (можуть бути також знайдені раніше не виявлені помилки). Для того, щоб метод був ефективним у
виявленні помилок, потрібна велика кількість мутантів, що можливо тільки при
автоматичній їх генерації.
5.
Методи, базовані на аналізі очікуваного використання.
До цієї категорії можна віднести два основних методи:
v статистичне тестування;
v тестування за операційним профілем.
При статистичному
тестуванні вхідні дані для проектування тестів вибираються з
вхідного простору відповідно до частоти їх появи в майбутніх сценаріях
використання програми. Під час виконання тестів фіксуються моменти відмов і обчислюються
інтервали між відмовами MTBF (Mean Time Between Failure), звичайно в одиницях
процесорного часу (CPU) або часу виконання. Отримана інформація
використовується для оцінки надійності і прогнозування моменту завершення
тестування. Метод застосовується на рівні системного тестування. Для визначення
частоти використання функцій програми, а також моментів відмов, у код вставляються команди-лічильники.
Тестування
за операційним
профілем застосовується в рамках методології інженерії
надійності (SRE, від Software Reliability Engineering) і
називається методом SRET (від Software Reliability Engineered Testing). Методологія SRE
охоплює повний цикл розробки програмних систем з підвищеними вимогами до
надійності, а тестування SRET (є по суті статистичним) базується на
впорядкуванні входів не лише за частотою, але і з урахуванням критичності
функцій, режимів і наслідків відмов систем під час експлуатації.
До
категорії методів, базованих на аналізі очікуваного використання, можна
віднести також метод тестування за сценаріями можливого використання, суть
якого полягає в ідентифікації можливих сценаріїв роботи користувача і розробці
за ними сценаріїв тестування (test-сases). Цей метод застосовується в усіх сучасних інструментах
автоматизації функціонального тестування програм, що мають графічний інтерфейс
користувача. Він також використовується в методології RUP (Rational Unify
Process), згідно якої сценарії тестування формуються на етапі аналізу і
проектування за наборами «прецедентів» (use-сases), а також MSF.
Узагальненням
даного методу можна вважати тестування на базі моделей (model-based testing, model-driven testing),
вживане в рамках відповідного підходу до розробки (model-driven development).
Такі
відомі підходи до тестування як тестування базоване на ризику (risk-driven testing, risk-based testing),
представляють не методи розробки тестів, а стратегії спрямованого тестування
для мінімізації наборів тестів. Ці стратегії подібні тестуванню за операційним
профілем, але проводяться методами систематичного тестування і враховують не
тільки частоту використання, але і величину ризику відмови ПЗ.
6.
Методи, що враховують специфіку програмної системи.
Розглянуті вище методи
універсальні і застосовні до будь-яких типів ПЗ. Проте вони не враховують характерних особливостей
побудови систем різного типу, що вимагають застосування специфічних підходів до тестування.
Виділено такі специфічні об’єкти
тестування:
Ø об’єктно-орієнтованих програм;
Ø компонентів;
Ø графічних інтерфейсів;
Ø Web-застосувань;
Ø систем реального часу;
Ø критичних систем.
Цей перелік не вичерпний,
він охоплює лише основні типи сучасних ПЗ. Особливості типів ПЗ обумовлюють не стільки
застосування спеціальних методів проектування тестів, скільки вибір методів і
видів тестування, найбільш ефективних для певних об’єктів тестування.
2. Стратегії
тестування, базовані на коді
До цих стратегій відносять методи
структурного тестування.
У традиційній класифікації
структурні методи відносять до методів «білого ящика». За цими методами
структура програми представляється у вигляді направленого графу, в якому ідентифікуються
потоки управління або потоки даних.
Категорії методів:
ü тестування потоку
управління;
ü тестування потоку даних;
ü тестування циклів.
З кожним методом
зв’язується критерій покриття, який
визначає ступінь повноти тестування за цим методом.
У методах структурного
тестування ці критерії називаються структурними
критеріями покриття.
3. Критерії покриття рядків,
розгалужень, покриття умов
В методах тестування потоку управління, дані з вхідного
простору вибираються так, щоб забезпечити максимальне покриття коду.
Покриття
коду визначає повноту перевірки модуля набором тестів.
Основні методи наведено
нижче:
1. Тестування рядків. Критерій покриття С0 (покриття рядків).
2. Тестування розгалужень. Критерій покриття С1 (покриття розгалужень).
3. Тестування логічних умов. Критерій покриття С2.
Ці методи використовуються на рівні модульного тестування (окремих методів класу).
1.
Тестування рядків. (Statement Coverage). Вибираються дані, що
забезпечують виконання всіх рядків (операторів) програми. Цей метод дає найслабший
критерій покриття, так зване «покриття рядків», і прийнятний для програм, що
не містять логічних умов і циклів.
2.
Тестування розгалужень. (Decision Coverage). Вибираються дані, що
забезпечують виконання шляхів, які виділяються в програмі за допомогою логічних
умов, що приймають значення True і False.
3. Тестування логічних умов.
Якщо розгалуження в
програмі утворюються в результаті виконання складних логічних умов, дані для їх
тестування повинні вибиратися так, щоб перевірити всі значення логічних умов.
Наприклад, для повної перевірки поданої нижче логічної умови:
if (A..................else ..................endif
необхідно вже чотири
тести (один — для випадку, коли умова виконується, і три — для решти випадків):
1) A < B і С = 1.
2) A < B і С ¹ 1.
3) A ³ B і C = 1.
4) A ³ B і С ¹ 1.
Цей метод дає найповніший
критерій покриття коду програми, який називається критерієм «логічні умови».
Знову таки, для
задоволення критерію покриття рядків було б достатньо одного тесту, а для
покриття розгалужень – двох.
4. Тестування циклів
Тестування циклів. Тести
розробляються для перевірки кожного циклу при граничних значеннях змінних циклу
і всередині них.
Цей метод дає критерій покриття, який
називається «всі цикли».
Приклад 11
using System;
namespace C_Sharp_Programming
class Cycles
{public static void Main()
{int nl, n2;
nl = 0;
n2 = nl + 1;
while(nl < n2)
{Console WriteLine ("nl, n2 = ", nl, n2 );
n1++;
n2++;
}}}}
У цьому прикладі умова (nl < n2) завжди вірна. Тому вихід з циклу неможливий. Отже, програма увійде до режиму вічного
циклу. Такі помилки є критичними, тому слід дуже уважно перевіряти умови виходу
з циклу.
Примітка.
Цикл while є найбільш “небезпечним” з точки зору тестування.
Приклад 12. Написати і
виконати тест для знаходження помилки в методі піднесення до ступеня числа x.
//Варіант 1
// Метод обчислення
ступеню n числа, xn (для n>0)
static public double Power(double x, int n)
{double z=1;
for (int i=1;n>=i;i++)
{z = z*x;
}return z;}
При n<1 метод буде видавати неправильний результат, наприклад:
Power(2,—1) = 2, але ніякої
діагностики не виводиться.
Отже, метод не стійкий до помилок у вхідних
даних.
// Варіант 2
// Метод обчислення
ступеню n числа xn (для n>0)
static public double PowerNonNeg(double x, int n)
{double z=1;
if (n>0)
{for (int i=1;n>=i;i++)
{z = z*x;}
}
else Console.WriteLine("Помилка! Показник ступеню повинен бути
>=0.");
return z;
}
Для цього прикладу розробимо тести для
перевірки розгалужень і циклу.
Метод приймає 2
параметри: double x, int n і повертає значення xn. Значення n>0.
Для спрощення тестування обмежимо n=100.
Крім перевірки вхідних параметрів, корисно
знайти обмеження для максимального значення xn .
Написати виклик
цього методу з методу main().
За допомогою цього
набору тестів ми перевірили всі рядки коду. Критерій С0=100%, розгалуження if
(). Критерій C1=100%. Цикл при min, max, проміжних значеннях змінної
циклу.
Але цей набір
недостатній для виявлення помилки виходу за розрядну сітку при дуже великих
значеннях xn.
Модифікуємо метод
для того, щоб він був стійким до помилок у вхідних даних.
Введемо обмеження на
дані, які будемо аналізувати.
1. Значення числа і
ступеня повинні бути цілими.
2. Значення числа,
що підноситься до ступеня, повинні знаходитись в діапазоні –
[0..999].
3. Значення ступеня
повинні знаходитись в діапазоні – [1..100].
Якщо числа, що
подаються на вхід, знаходитись за межами вказаних
діапазонів, то повинне видаватися повідомлення про помилку.
У метод Main вставимо обробку
виключень (блок try{} catch (Exception e))
// Метод обчислення
ступеню n числа x
static public double Power(int x, int n)
{double z=1;
for (int i=1;n>=i;i++)
{z = z*x;
}return z;
}[STAThread]
static void Main(string[] args)
{
int x;
int n;
try
{
Console.WriteLine("Enter x:");
x=Convert.ToInt32(Console.ReadLine());
if ((x>=0) & (x<=999))
{
Console.WriteLine("Enter n:");
n=Convert.ToInt32(Console.ReadLine());
if ((n>=1) & (n<=100))
{
Console.WriteLine("The power n of x is
{0}",
Power(x,n));
Console.ReadLine();
}
Else
{
Console.WriteLine("Error : n must be in
[1..100]");
Console.ReadLine();
}}
Else
{Console.WriteLine("Error : x must be in
[0..999]");
Console.ReadLine();
}}
catch (Exception e)
{
Console.WriteLine("Error : Please enter a
numeric argument.");
Console.ReadLine();
}}
Загальні правила проектування тестів. Тести
розробляються спочатку для перевірки правильних вхідних даних і умов.
Обов’язково для граничних даних і після цього для неправильних вхідних даних і
умов.
Тестування потоків даних
У методі тестування
потоку даних тестові дані вибираються так, щоб відслідкувати шляхи
кожної змінної в програмі від призначення значень до самого останнього
використання (для всіх змінних). Цей метод вимагає великої кількості тестів,
тому на практиці трасуються найбільш критичні значення змінних. Особливий
інтерес, наприклад, представляють значення змінних, що беруть участь в операціях
ділення, умови і цикли, виконання яких залежить від значень змінних. Метод
тестування потоку даних може також застосовуватися для пошуку помилок часу
виконання, зв’язаних з використанням пам’яті, які важко знаходяться.
Приклад: написати
метод, розробити для нього тести і виконати їх.
Перевірити при x=0.
static void main()
{
double x,y;
Console.WriteLine("Введіть значення x (double)");
x= double.Parse(Console.ReadLine());
y = Math.Sin(x)/x;
Console.WriteLine ("y = " + y);
}
При x=0 буде помилка ділення на 0.
На практиці в
одному модулі (методі, процедурі) зустрічаються і цикли і умовні оператори.
Тому розробляються комбіновані набори тестів для покриття всіх критерієв (і
циклів і розгалуджень).
Які типи помилок не можна виявити методами
структурного тестування:
1.
Невідповідність специфікації.
2.
Помилки в інтерфейсі користувача.
3.
Реакція на обробку подій.
4.
Зручність використання.
Питання для самоконтролю:
1. Які методи тестування Ви
знаєте?
2. Опишіть класифікацію
методів.
3. Як відбувається тестування потоку даних.
4. Як відбувається
тестування циклів.
5. Охарактеризуйте стратегії тестування.

