Лекція 5. Зв’язки та штучні ключі у реляційній БД
1. Зв’язки (відношення) у реляційній БД.
2. Штучні (сурогатні) ключі.
1. Звя’зки (відношення) у реляційній БД.
У загальному зв’язки поділяються на два основні типи:
А) Бінарні зв’язки.
Б) Небінарні зв’язки (тернарні, кватернарні і т.д.).
А. Бінарні зв’язки – це зв’язки між двома таблицями.
Розрізняють такі типи зв’язків:
1) 1:1, «один до одного».
2) 1:М, «один до багатьох».
3) М:М, «багато до багатьох».
4) Рекурсивні.
Зв’язки 1:1 та 1:М представляють собою клас зв’язків, де одна таблиця передає свій потенційний ключ іншій таблиці у якості зовнішнього ключа. Таблиця, що містить потенційний ключ, відома як таблиця предок, а таблиця, що отримує та використовує його у якості зовнішнього ключа, як таблиця нащадок.
Ця термінологія предків-нащадків розглядається лише для зв’язків між двома конкретними таблицями.
1) Зв’язок «один до одного» (рис.1) означає, що для будь-якого конкретного предка може існувати лише один єдиний нащадок. Наприклад, кожна людина має лише єдине місце народження. Однією з причин, чому ці дані потрібно зберігати в окремих таблицях, а не в одній, може бути питання конфіденційності. СКБД забезпечують безпеку даних на рівні таблиці, а не на рівні стовпців. Друга причина
пов’язана з продуктивністю систем БД. Наприклад, стовпці з даними, що мають значну довжину чи містять великі бінарні об’єкти та рідко використовуються, для пришвидшення оброблення запитів можуть бути винесеними у іншу таблицю.
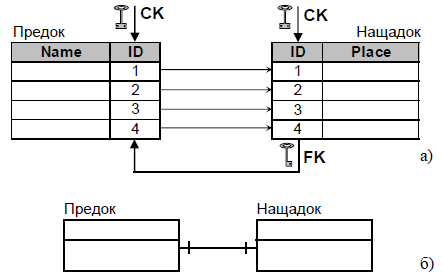
Рис. 1. Зв’язок «один до одного»
а) реалізація; б) спрощена структурна схема
2) Зв’язок «один до багатьох» (рис.2) означає, що для кожного предка може бути необмежене число записів-нащадків. Правильніше було б називати цей зв’язок, як «один до довільного числа», оскільки він охоплює зв’язки «один до нуля», «один до одного» та «один до багатьох».
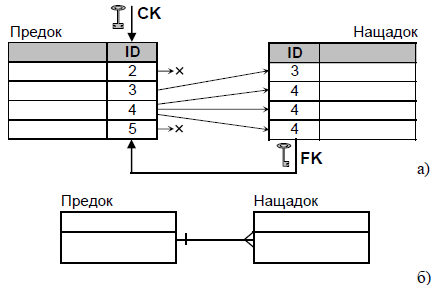
Рис. 2. Зв’язок «один до багатьох»
а) реалізація; б) спрощена структурна схема
Зв’язки 1:М поділяються на такі підкласи:
а) ідентифікуючий або неідентифікуючий зв’язок;
б) обов’язковий або необов’язковий зв’язок (для неідентифікуючого зв’язку).
Ідентифікуючий зв’язок (рис.3) з’єднує дві таблиці, у яких первинні ключі чи їхня частина співпадають. Тобто, потенційний ключ з базової таблиці мігрує у первинний ключ підлеглої таблиці.
Чому ідентифікуючий??? → Для того, щоб мати можливість визначати запис у таблиці нащадку, ми обов’язково повинні мати відповідний йому запис у таблиці предку. Без існування, відповідно, останнього не може існувати перший.
Приклад 1. Замовлення на постачання та перелік його елементів.
Без замовлення на постачання – елементи не мають ніякого змісту.
Приклад 2. Зв’язок 1:1, як підвид зв’язку 1:М.
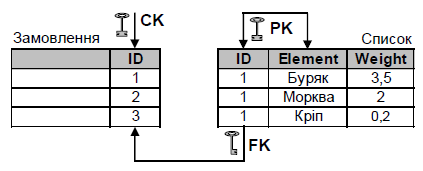
Рис. 3. Приклад ідентифікуючого зв’язку
Неідентифікуючий зв’язок (рис.4) означає, що потенційний ключ з базової таблиці не мігрує у первинний ключ таблиці-нащадка. Такий тип зв’язку часто використовують при посиланні на довідкову таблицю або з метою уникнення аномалій вставки (тоді усі допустимі значення виносяться у додаткову таблицю, а між таблицями встановлюється неідентифікуючий зв’язок, що забезпечує цілісність
посилань).
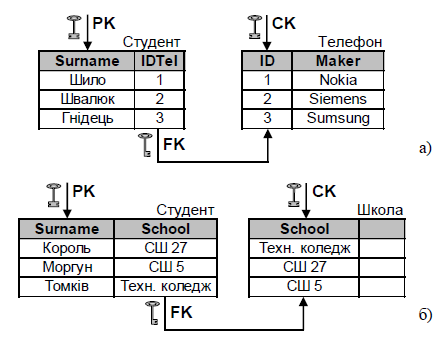
Рис. 4. Приклади неідентифікуючого зв’язку
3) Зв’язок «багато до багатьох» (рис.5) означає, що для запису деякої одної таблиці ставляться у відповідність записи іншої таблиці, і навпаки, запису іншої таблиці ставляться у відповідність записи першої. Тут немає чітко вираженого предка та нащадка. Наприклад, клієнтам продають різні товари, тобто один клієнт може вибрати декілька товарів, а кожен товар може бути вибраний декількома клієнтами. У СКБД такий зв’язок реалізується за допомогою 2-х зв’язків 1:М та додаткової стикувальної таблиці.
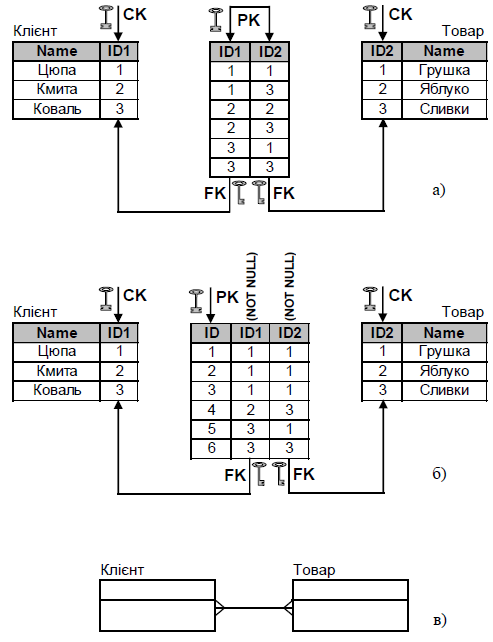
Рис. 5. Зв’язок «багато до багатьох»
а) реалізація; б) альтернативна реалізація;
в) спрощена структурна схема
4) Рекурсивний зв’язок означає, що потенційний та зовнішній ключі, із встановленою між ними залежністю, належать одній таблиці.
Його ще називають унарним зв’язком.
Існує три класи рекурсивних зв’язків:
а) 1:1 (список);
б) 1:М (дерево);
в) М:М (сітка).
а) Рекурсивний зв’язок «один до одного» (рис.6) реалізує структуру даних типу «список».
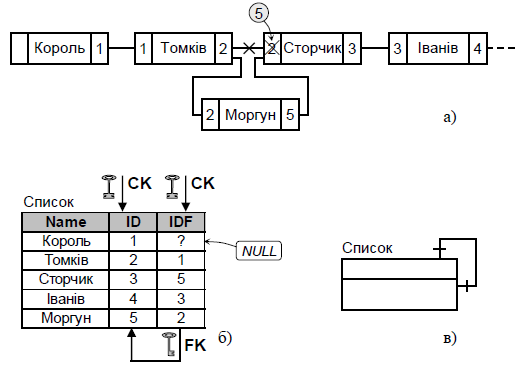
Рис. 6. Рекурсивний зв’язок «один до одного»
а) реалізація; б) альтернативна реалізація;
в) спрощена структурна схема
б) Рекурсивний зв’язок «один до багатьох» (рис.7) реалізує структуру даних типу «дерево».
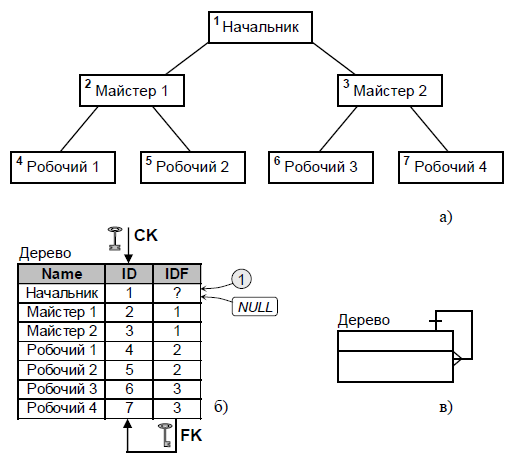
Рис. 7. Рекурсивний зв’язок «один до багатьох»
а) ілюстрація; б) реалізація; в) спрощена структурна схема
Для зв’язків 1:1 та 1:М існує дилема «першого запису» (зовнішній ключ вимагає значення потенційного ключа для уже внесеного у таблицю запису). Є два шляхи вирішення цієї дилеми:
1. Перед створенням зовнішнього ключа необхідно ввести у таблицю перший запис, який потім буде посилатися на себе ж самого, або, навпаки, створити зовнішній ключ, а потім відмінити його дію на деякий час, поки не буде внесено перший запис.
2. Стовпець для зовнішнього ключа повинен дозволяти введення NULL-значення. Таким чином, з’явиться можливість ввести першу стрічку, що має NULL-значення у стовпці зовнішнього ключа, і тим самим уникнути необхідності примусового введення першої стрічки.
в) Рекурсивний зв’язок «багато до багатьох» (рис.8) реалізує структуру даних типу «сітка». Наприклад, поліклініка у якій лікарі лікують один одного.
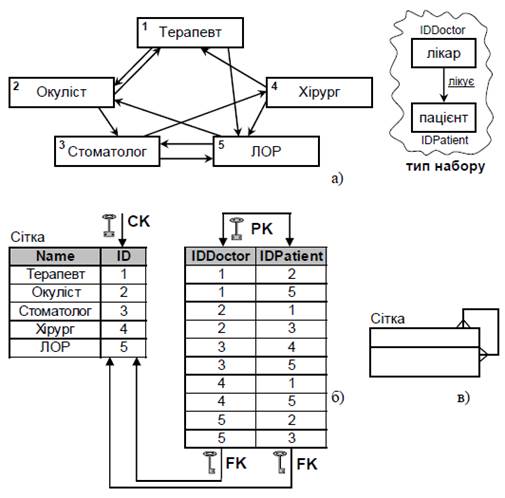
Рис. 8. Рекурсивний зв’язок «багато до багатьох»
а) ілюстрація; б) реалізація; в) спрощена структурна схема
Б. Небінарні зв’язки – це зв’язки між трьома та більше таблицями.
Приклад потрійного (тернарного) зв’язку (рис.9):
1. є певний асортимент піц;
2. є перелік клієнтів, що замовляють ці піци. Потрійний зв’язок
полягає у тому, що будь-які піци можуть бути доставлені
різним клієнтам, і при цьому довільним рознощиком.
* Аналогія: студент, викладач, знання.
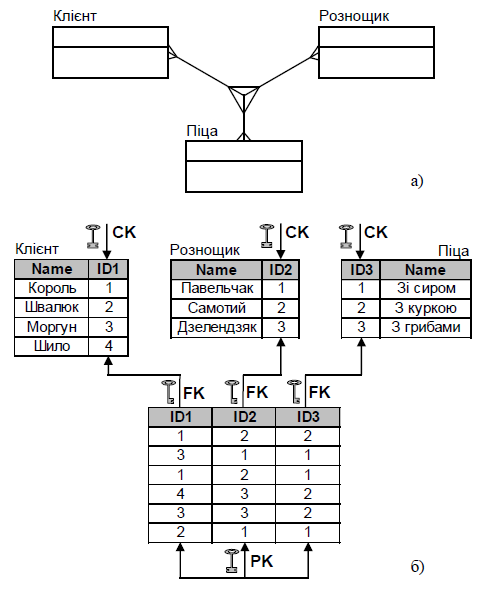
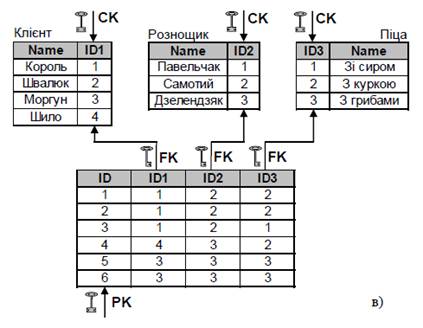
Рис. 9. Тернарний зв’язок а) спрощена структурна схема;
б) реалізація; в) альтернативна реалізація
2. Штучні (сурогатні) ключі.
Сурогатний ключ – це унікальний ідентифікатор, що надається системою БД для використання його у якості потенційного ключа таблиці. Він не має жодного змісту для користувача, і тому, як правило, не відображається на формах та у звітах. Надане СКБД для нього значення не підлягає зміні, тобто є заблокованим. Існує два способи утворення сурогатних ключів:
1) за допомогою автоінкрементних полів;
2) за допомогою GUID-ідентифікаторів.
1) Автоінкрементне поле може бути побудоване на основі стовпця з цілим або десятковим типом (для десяткового типу не дозволено мати цифри після коми, тобто його степінь має дорівнювати нулю). Для автоінкрементного поля можуть бути задані початкове значення та значення приросту (інкременту), за замовчуванням вони рівні одиниці. Початкове значення встановлюється системою для найпершої стрічки таблиці, а для наступних стрічок генерується із врахуванням приросту. Значення приросту може бути як додатним, так і від’ємним. Значення ідентифікатора видалених стрічок уже більше нікому не присвоюються, а наступне значення генерується відносно останнього зафіксованого для таблиці значення. У таблиці може існувати, як правило, лише одне автоінкрементне поле (рис. 10).
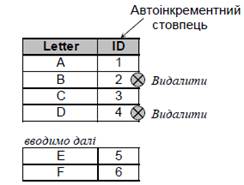
Рис. 10. Ілюстрація принципу роботи автоінкрементного поля
2) GUID-ідентифікатор – це глобальний унікальний ідентифікатор стрічок. Він представляє собою 16-байтну величину, наприклад, 39f7b233-5f0b-45b7-b496-491ddec81b3d.
Значення для GUID-ідентифікатора генеруються на основі номера мережевої плати та значення системного часу. Унікальність номерів мережевих плат гарантується їхніми виробниками у найближчі 100 років.
Необхідність використання GUID-ідентифікаторів пов’язана зі ситуацією, коли потрібно об’єднувати дані із різних БД, і при цьому гарантувати унікальність, наприклад, рахунків клієнтів чи номерів соціального страхування.
Є дві причини використання сурогатних ключів:
а) прагматична;
б) філософська.
а) Прагматична причина. Наприклад, ми маємо дві таблиці зі зв’язком між ними «багато до багатьох». У кожній таблиці є задано первинний ключ стрічкового типу UNICODE на 50-т символів. Для організації зв’язку М:М необхідно ще створити додаткову стикувальну таблицю, в яку будуть мігрувати первинні ключі базових таблиць (рис.11).
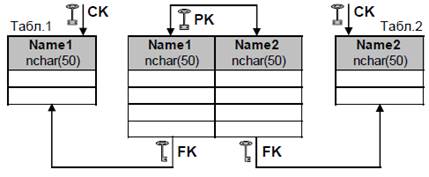
Рис. 11. Зв’язок М:М з великими ключами
Проблема: стикувальна таблиця буде дуже великого розміру, плюс дуже об’ємний її первинний ключ. Наприклад, таблиця 1 має 100 записів, таблиця 2 має теж 100 записів; при усіх можливих комбінаціях зв’язку М:М стикувальна таблиця може мати до 10 тис. записів (!!!).
Вирішення проблеми: ввести у таблицю 1 і таблицю 2 сурогатні ключі на основі автоінкрементрих 32-х бітних полів цілого типу (рис.12).
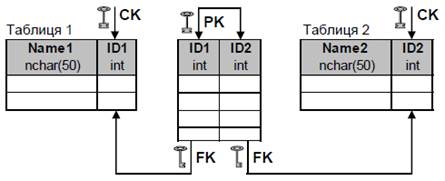
Рис. 12. Ілюстрація використання сурогатних ключів
Висновок: якщо первинний ключ таблиці є довгим текстовим полем чи композитним ключем, що містить довгі текстові елементи, тоді варто подумати про використання сурогатних ключів.
б) Філософська причина полягає у тому, що сурогатні ключі підтримують унікальну ідентифікацію стрічок базової таблиці.
Наприклад, якщо композитний ключ складається з 3-х полів П.І.Б., і виникає ситуація, що необхідно ввести ще одну особу, яка вже має свого двійника у таблиці, то виникає казус. Архітектура БД не повинна обмежувати користувачів у такий спосіб.
Інший приклад, коли необхідно змінити значення первинного ключа, що мігрує в інші таблиці, а підтримка такої можливості не передбачена, наприклад, зміна прізвища.
Недоліки використання сурогатних ключів: інформативні ключі, що мігрують у інші таблиці, виключають додатковий пошук у базовій таблиці за їхніми значеннями, тобто вже певна частина важливої інформації мігрує у зв’язані таблиці, наприклад, назва групи для студентів.
Питання для самоперевірки:
1. Охарактеризуйте бінарні зв’язки.
2. Охарактеризуйте небінарні зв’язки..
3. Використання штучних «сурогатних» ключів.
4. Проблеми використання штучних ключів.
5. Рекурсивний зв’язок.