Лекція №2
Моделі даних
1. Поняття про моделювання даних. Класифікація моделей.
Дані та їхня семантика
Слово «дані» походить від латинського «datum» ‒ факт, проте дані не завжди відповідають конкретним чи навіть реальним фактам. Іноді вони неточні або описують те, чого насправді не існує.
Даними вважають опис будь-якого явища (чи ідеї), що викликає зацікавленість через певні потреби. З даними нерозривно пов'язана їхня інтерпретація (або семантика), тобто той зміст, який їм приписується.
Дані описуються тією чи іншою мовою і фіксуються на певному носії (скажімо, папері). Зазвичай дані (факти) та їхня семантична інтерпретація фіксуються спільно. Проте в деяких випадках дані й інтерпретація розділяються. Так, у зведеній статистичній таблиці зверху, в її шапці, міститься інформація стосовно того, чим є дані (заголовок таблиці, описова інформація, назви стовпців тощо), а нижче розташовуються власне рядки чисел.
Застосування комп'ютерів для введення й обробки даних сприяло ще більшому розділенню даних та їхньої інтерпретації. Оскільки комп'ютери оперують даними як такими, велика частина інтерпретуючої інформації взагалі явно не фіксується. Програма одержує певні вхідні дані, обробляє їх і видає результат у вигляді сукупності вихідних даних.
Засоби інтерпретації даних мають бути гнучкими, аби разом з незмінними параметрами даних відображувати й аспекти їхньої еволюції. Цього досягають двома способами. По-перше, можна відтворювати різні погляди на одні й ті самі дані. Наприклад, розглядати певну особу з точки зору кадрової системи як службовця, з погляду виробничих інтересів − як виконавця робіт, а з боку медичного обслуговування − як пацієнта. По-друге, різні дані можна подавати одноманітно. Так, адміністратори, клерки, агенти, секретарі незалежно від роду своєї діяльності можуть розглядатися в кадровій системі як службовці.
Моделювання даних
Існує багато типів моделей фізичні, математичні, економічні тощо, які відображують різні аспекти реального світу. Модель даних відображає уявлення про реальний світ. Проте, важливо, аби обсяг знань і семантика даних, відтворені в моделі, були адекватні способу використання даних.
Вважатимемо, що модель даних ‒ це сукупність структури даних, операцій над ними (операції маніпулювання даними) та обмежень цілісності. Іншими словами, модель визначає, в який спосіб відбувається об'єднання даних у структури різної складності, які існують обмеження на значення даних і як здійснюється оперування цими даними
Основою для будь-якої структури даних є відображення елементарної одиниці даних у вигляді такої трійки: об'єкт, властивість об'єкта, значення властивості. Сукупність взаємопов'язаних між собою елементарних одиниць даних може відображуватися різноманітними способами, що приводить до формування різних структур, а відтак ‒ різних моделей даних. Моделі даних поділяються на два класи: сильно та слабко типізовані.
У сильно типізованих моделях усі дані мають належати до певної категорії, або типу. Якщо дані не підпадають під жодну з категорій, їх потрібно типізувати штучно. Деякі моделі будуються у такий спосіб, що категорії визначаються наперед і не можуть змінюватися динамічно. У цьому випадку модельований світ начебто вміщується в гальмівну сорочку. Наприклад, категорія «службовець» ‒ строго фіксована, й усі її об'єкти повинні мати однакові властивості та структуру. Сильно типізовані моделі мають значні переваги, бо дають змогу побудувати абстракції властивостей даних і дослідити їх у термінах категорій. Більшість моделей, що використовуються в автоматизованих системах, зокрема й базах даних, належать до сильно типізованих.
Для слабко типізованих моделей належність даних до тієї чи іншої категорії не має жодного значення. Категорії використовуються настільки, наскільки це доцільно в кожному конкретному випадку. Окремі дані можуть існувати як незалежно, так і у зв'язку з іншими. Інформація про категорії (якщо вони використовуються) розглядається як додаткова.
На відміну від сильно типізованих моделей, слабко типізовані забезпечують інтеграцію даних і категорій. Найкращі можливості такої інтеграції надаються численням предикатів, яке у багатьох моделях даних використовується для зображення знань, що не підтримуються базовими засобами моделювання.
Відомі три класичні моделі баз даних: ієрархічна, мережна та реляційна (рис.1). (У базах знань використовуються інші моделі, але про них мова йтиме далі.)
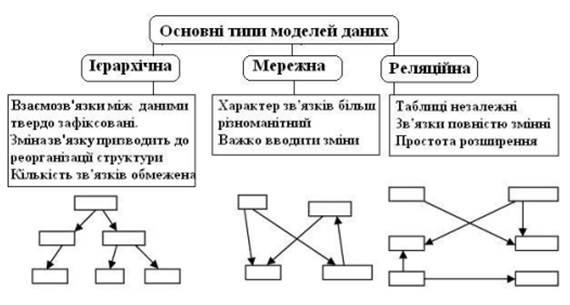
Рис.1. Основні типи моделей даних
2. Картотеки
Картотека – впорядковане зібрання даних, як правило, на карточках невеликого формату, та представляє собою каталог певної БД. Кожна картка є інформаційною одиницею та, з метою полегшення пошуку, містить відомості про певний об’єкт за визначенимиознаками. Впорядкування здійснюється обов’язково згідно логічних критеріїв: за алфавітом, датою і т.п. У кінці 19 ст. було запропоновано ноу-хау: картки з перфорацією на краю. Згідно пробитих отворів кодувалися дані, що записані на картці.

Рис.2. Картка з картотеки
Картотека може бути внесеною в електронну базу даних. На відміну від БД, картотека складається, як правило, з єдиного зібрання ідентичних за структурою карток. Електронним аналогом картотеки є таблиця БД. Одна картка відповідає одній стрічці електронної таблиці.
Приклади: картотека пацієнтів у поліклініці, каталог бібліотеки.
3. Ієрархічна модель даних.
Вважається, що розвиток СКБД почався ще в1960-ті роки, коли розроблявся проект запуску корабля Apollo на Місяць. Цей проект був започаткований за ініціативою президента США Кеннеді, який поставив чітку задачу щодо виконання пілотованого польоту та висадки людини на Місяць до кінця десятиліття. Нажаль, в цей час не існувало жодних систем, здатних оброблювати чи керувати тією великою кількістю даних, що була необхідна для реалізації цього проекту.
У результаті спеціалісти основного підрядника – компанії North American Aviation (яка зараз називається Rockwell International) – розробили програмне забезпечення під назвою GUAM. Його основна ідея була побудована на тому, що малі компоненти об’єднуються разом як частини дещо більших компонентів до того часу, аж поки не буде зібрано воєдино цілий проект. Використана при цьому структура нагадує перевернуте дерево і має назву ієрархічної структури.
У середині1960-х років корпорація IBM приєдналася до фірми North American Aviation для сумісної роботи над GUAM, у результаті чого була створена система IMS (Information Management System). Причина, згідно якої корпорація IBM обмежила функціональні можливості IMS тільки для керування ієрархіями записів, полягала у необхідності забезпечення роботи з пристроями зберігання з послідовним доступом, а саме з магнітними стрічками, що на той час були основним типом носія. Із всіх комерційних СКБД – IMS і надалі залишається основною ієрархічною СКБД.
У першій ієрархічній системі були повністю реалізовані функції СКБД, а саме: мови визначення та маніпулювання даними, опис і підтримка обмежень цілісності, паралелізм, відновлення, а також механізми ефективної обробки запитів. Варто сказати, що IMS і досі використовується на мейнфреймах.
У ієрархічній моделі зв’язки між даними описуються за допомогою дерева, що схематично зображено на рис. 3.
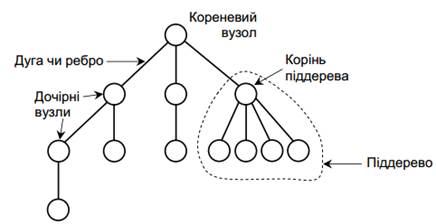
Рис. 3. Узагальнене представлення деревовидної структури
Ієрархічна структура даних
Ієрархічна структура даних визначається ієрархічною впорядкованістю своїх компонентів (або вузлів), тобто кожен вузол має не більше одного «батька» ‒ старшого за ієрархією вузла.
Структура складається зі схем елементів даних (описова інформація) та їхніх екземплярів. Інакше кажучи, схема задає логічну структуру (або тип) елементу даних, а екземпляр ‒ його значення.
Елементарним значенням структури є іменоване поле даних, а його екземпляр ‒ це елементарне значення.
Схема сегмента (яку називатимемо також просто сегментом) ‒ це іменована впорядкована сукупність імен полів. Сегмент є одиницею доступу до даних ієрархічної структури під час взаємодії зовнішньої та оперативної пам'яті.
Екземпляр сегмента ‒ впорядкована сукупність значень полів.
Ієрархічна схема даних ‒ це ієрархічно впорядкована сукупність сегментів, що має певні властивості:
♦ на найвищому рівні ієрархії розташований єдиний сегмент, що називається кореневим;
♦ кожен інший сегмент, окрім кореневого, зв'язаний з одним і тільки одним сегментом вищого рівня, який є для цього сегмента батьківським (початковим);
♦ сегмент може бути зв'язаний з одним або кількома сегментами нижчого рівня, які називаються дочірніми (породженими);
♦ сегменти, що підпорядковані одному батьківському сегменту, називаються близнюками;
♦ сегменти, що не мають дочірніх, вважаються листковими, або їх ще називають листками.
Ієрархічний шлях (або просто шлях) ‒ це послідовність сегментів, починаючи з кореневого, де кожний попередній є «батьком» наступного. Рівень сегмента визначається як кількість сегментів, що містяться на шляху, який веде від кореня до даного сегмента.
Для ієрархічної схеми використовується така графічна нотація:
♦ Кожний сегмент зображується у вигляді пойменованого прямокутника. Усередині прямокутника записуються імена полів.
♦ Ієрархічний зв'язок між сегментами позначається лініями зі стрілками, що проведені від батьківського сегмента до дочірнього. Батьківські сегменти, як правило, розміщують над дочірніми.
Приклад графічного зображення простої ієрархічної схеми даних наведений на рис. 3, а. Якщо немає необхідності уточнювати сегменти полями, що зазвичай робиться під час загального аналізу ієрархічної структури предметної області, то в прямокутнику сегмента зазначається його ім'я (рис. 4, б).
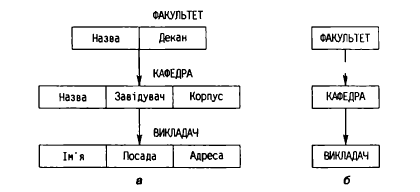
Рис. 4. Графічне зображення схеми ієрархічної структури даних:
з уточненнями (а); без уточненнь (б)
Екземпляр ієрархічної схеми даних складається з одного екземпляра кореневого сегмента і, можливо, кількох екземплярів дочірніх сегментів для кожного екземпляра батьківського сегмента. Припускається існування таких зв'язків між екземплярами сегментів:
♦ кожний екземпляр будь-якого сегмента підпорядкований одному екземпляру батьківського сегмента;
♦ екземпляр будь-якого сегмента (окрім кореневого) не може існувати без відповідного екземпляра батьківського сегмента;
♦ кожний екземпляр сегмента зв'язаний (підпорядковує собі) з усіма екземплярами дочірніх сегментів;
♦ екземпляри одного сегмента, зв'язані з одним екземпляром батьківського сегмента, можуть бути зв'язані між собою в ланцюжок, що дає змогу виконувати їхнє послідовне перебирання у межах усіх сегментів, породжених з одного початкового.
У такий спосіб ієрархічна впорядкованість сегментів створює зв'язок «один-
до-багатьох» між екземплярами батьківського і дочірнього сегментів. Приклад екземплярів ієрархічної схеми наведений на рис. 5.
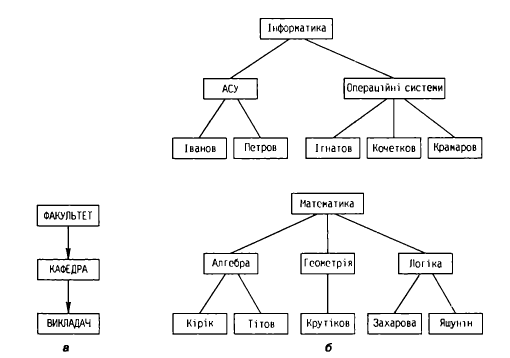
Рис. 5. Схема (а) та її екземпляри (б) в ієрархічній структурі даних
Ієрархічна схема інколи має розгалуження, як це показано на рис. 6. У подібному випадку на рівні схеми батьківський сегмент може зв'язуватися з кількома дочірніми сегментами.
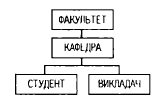
Рис. 6. Ієрархічна схема з розгалуженням
Ієрархічна структура даних — це сукупність ієрархічної схеми даних та всіх можливих екземплярів цієї схеми. Сукупність ієрархічних структур даних називається ієрархічною базою даних.
Операції над ієрархічною структурою
Операції, що виконуються над ієрархічною структурою, поділяють на дві групи: операції пошуку (чи вибирання) та операції оновлення даних (або маніпулювання ними).
Зазначимо кілька базових принципів, характерних для мов маніпулювання даними ієрархічних систем.
♦ Об'єктом маніпулювання є екземпляр сегмента.
♦ У результаті успішного виконання пошукових операцій визначається поточний екземпляр сегмента, який може відігравати роль стартової позиції для операцій маніпулювання; спочатку поточним є кореневий екземпляр сегмента.
♦ Пошук необхідного сегмента відбувається за «навігаційним» принципом: необхідно прокласти шлях від кореневого екземпляра сегмента (або ж поточного) до шуканого, перевіряючи умови, накладені на значення полів сегментів, які розташовані на шляху, що будується. Операція в ієрархічній моделі визначається шляхом програмування «навігації» структурою даних.
Вибирання даних
Необхідний екземпляр сегмента вибирається в ієрархічній структурі за допомогою команди «навігації» структурою. Екземпляр сегмента є одиницею навігації.
Для визначення необхідного сегмента навігації може накладатися умова на значення полів сегмента. Відносно поточного сегмента можна переміщуватися ієрархічною структурою вверх, вниз і вбік.
Навігацію ієрархічною структурою можна здійснювати з метою її впорядкування, а потім переміщуватися нею згідно зі встановленим порядком. Порядок переміщення встановлюється, починаючи з кореня або будь-якого первинного сегмента. Далі рухатись можна зверху донизу і зліва направо.
Маніпулювання даними
Маніпулювання даними передбачає додавання, заміну та видалення екземплярів сегментів специфікованих типів. Додати новий екземпляр сегмента можна лише за умови, що в ієрархічній структурі вже є екземпляр його батьківського сегмента.
Переваги та недоліки ієрархічної структури
До переваг ієрархічної моделі даних відносять ефективне використання пам’яті комп’ютера та непогані характеристики часу виконання основних операцій над даними. Ієрархічна модель даних є зручною для роботи з ієрархічно впорядкованою інформацією.
Недоліками ієрархічної моделі є її громіздкість для оброблення інформації з достатньо складними логічними зв’язками, а також складність її розуміння для звичайного користувача.
Основні недоліки ієрархічної моделі пов'язані з тим, що не всі предметні області мають чітко виражену ієрархічну структуру. Наведений на рис. 5 приклад добре узгоджується з ієрархічною структурою. Проте, якщо ми розглянемо предметну область із сутностями «викладач», «дисципліна», «лекція» в ситуації, коли один викладач читає лекції з багатьох дисциплін і одна й та сама дисципліна читається багатьма викладачами, то вона «погано» піддається ієрархічній структуризації. Справа в тому, що між викладачами і дисциплінами існує зв'язок типу «багато-до-багатьох», який не є адекватним ієрархічній структурі даних.
Для відображення зв'язків цього типу була запропонована мережна модель даних.
Приклади ієрархічних СКБД:
1) IMS (Information Management System) фірми IBM (перша версія 1968 р.);
2) TDMS (Time-Shared Data Management System) компанії Development Corporation;
3) System-2000 виробництва SAS-Institute;
4) Сервери каталогів, такі як Active Directory (допускають чітке представлення у вигляді дерева);
5) Реєстр операційної системи Windows, що побудований за принципом ієрархічної БД.
Питання для самоперевірки:
1. Дайте визначення поняття «моделювання даних».
2. Які ви знаєте типи моделей даних?
3. Що ви знаєте про картотеки?
4. Розкажіть про ієрархічну модель даних.
5. Які основні операції можна проводити над ієрархічною моделлю даних?